
SG-Nav
SG-Nav:一种利用实时三维场景图提示的大语言模型零样本物体导航方法
Q1:零样本物体导航(Zero-shot Navigation)是什么?
答:零样本,意思是没有在目标任务上做专门训练,直接“拿来用”。本文借助 大语言模型 (LLM)来实现物体导航,因为 LLM 有很强的语言和常识理解能力。
摘要
现有的零样本物体导航方法,通常是用 **“和目标物体空间上接近的物体的文字信息” **来提示大语言模型。 **但是 **,这样做缺乏足够的场景上下文,所以 LLM 的推理能力发挥不出来,推理不够深入。
举例:
机器人看到“桌子、椅子”,就提示 LLM —— 但 LLM 只知道这些名字,不知道它们之间的空间关系(比如桌子在厨房里、椅子靠近冰箱)。
为了更好地保留环境信息,并充分发挥 LLM 的推理能力,作者提出用 三维场景图(3D Scene Graph) 来表示观察到的场景。场景图把 物体、群组(objects groups)、房间 之间的关系,编码成一种适合 LLM 理解的结构。作者为此设计了一个 分层的“链式思维”提示(hierarchical chain-of-thought prompt),让 LLM 能够沿着场景图的节点和边去推理,最终推断目标物体可能的位置。
场景图 = 节点(物体/房间/群组) + 边(它们的关系)
就像 LLM 在一张“关系地图”里,一步一步地“走节点”,从环境线索推出目标在哪。
此外,得益于场景图的表示,作者还设计了一种 重新感知机制(re-perception mechanism),让导航框架能够在出现“感知错误”时进行修正。
作者在 MP3D、HM3D、RoboTHOR 这几个导航环境上做了大量实验。结果表明:SG-Nav 在所有基准上比之前最好的零样本方法 **成功率(SR)提升超过 10% **,而且整个决策过程是可解释的(可以看出 LLM 是怎么推理的)。SG-Nav 是第一个 在 MP3D 这个困难的环境上,零样本方法居然超过了有监督方法性能 的工作。
这说明 SG-Nav 真的很强。
通常情况下 零样本 < 有监督,但作者的方法反而超过了。
引言
物体巡航(Object-goal Navigation)是具身智能的一大基础任务,旨在让机器人在未知环境中通过主动探索巡航找到指定类别的物体。具体而言,机器人在任务开始时会被置于位置环境中,在接下来的每个时刻,输入信息为机器人相机对场景的RGB-D观测和对应相机参数,机器人需要在每个时刻预测自身的action,通常包含前进、左转、右转和停止。机器人预测停止时,任务结束,如果机器人在限定步数内位于目标物体附近,则任务成功。
以前的方法
以前基于深度学习和强化学习的 模块化物体导航方法 做得很好:它们会把视觉观测(RGB-D 图像)生成语义地图(Semantic Map),然后学习一个策略(Policy),根据地图预测机器人应该做什么动作。、
这些方法的 缺点 是:
需要在模拟环境中耗时训练
只对特定数据集有效
只能处理有限的目标物体类别。
Q2:什么是模块化物体导航?
答: **模块化 **指的是把导航任务拆分成多个功能模块,每个模块完成不同的子任务,然后组合起来实现整体导航。
一个典型的 模块化物体导航系统 会包括感知模块、语义理解模块、规划模块、动作控制模块。
为了克服这些限制,提高物体导航的 泛化能力(能在各种环境里工作),出现了基于LLM的零样本导航。
零样本导航
其 **优点 **是:
不需要在真实任务上训练或微调
目标类别可以用文本自由指定(开放词汇)
但是也存在以下 **问题 **:
只给 LLM 提示附近物体类别,信息量少,没有场景上下文(比如空间关系)
让 LLM 直接输出 前沿可能性 ,这个任务太抽象,没有充分利用 LLM 的推理能力
这可能导致 **推理过程不可解释 **,性能不够好。
Q3:前沿(frontier)是什么?
答:本文中,frontier(前沿)指的是已知区域和未知区域之间的边界点或区域,是导航和探索时选择下一个探索目标的重要候选位置。
SG-Nav方法介绍
本文提出新的物体导航框架 SG-Nav,充分利用 LLM 推理能力,实现高精度、快速的零样本导航。不同于以前只用物体类别文本直接输出概率的 LLM 导航方法,SG-Nav 用在线更新的层次化 3D 场景图表示复杂环境,并分层提示 LLM,实现 **可靠且可解释的决策 **。
首先随着智能体的探索实时构建 **层次化 3D 场景图 **,然后提出以增量方式将新检测到的节点与之前节点密集连接,并设计了一种新型提示来控制该密集连接过程的计算复杂度,使其随新节点数量线性增长,随后进行剪枝以丢弃信息量较少的边。
利用 3D 场景图,作者将其划分为若干子图,并提出 **层次化链式思维 **,让 LLM 感知每个子图中的结构信息,以进行可解释的概率预测。然后将每个子图的概率插值到前沿以进行决策,同时可以通过总结最相关子图的推理过程来进一步解释决策。
此外,以前的物体导航框架在检测到误报目标物体时会失败。因此,作者提出一种 基于图的重新感知机制 ,通过累积子图的相关概率来判断观察到的目标物体的可信度。智能体会放弃可信度低的目标物体,以实现更稳健的导航。
创新点 = 3D场景图 + 分层提示 LLM + 可解释决策
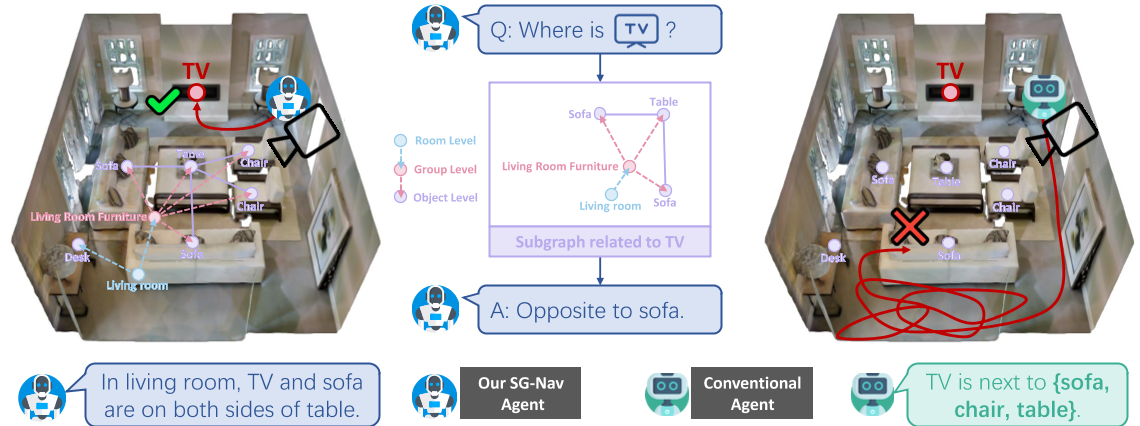
图1:不同于以往的零射击目标导航方法直接用附近物体类别的文本提示 LLM,作者构建了一个分层的三维场景图来表示观察到的环境,并提示 LLM 充分利用图中的结构信息。
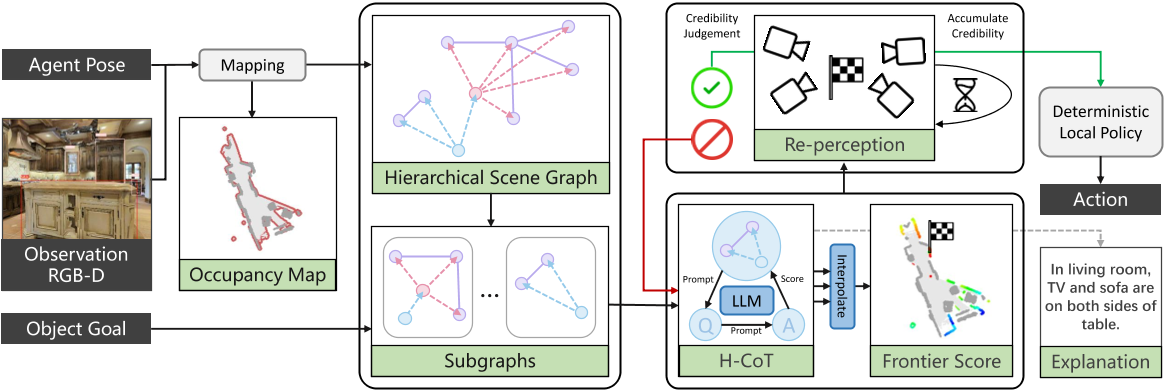
图2:SG-Nav的流程。作者在线构建了一个分层的 3D 场景图以及占据图。在每一步中,将场景图划分为若干子图,每个子图都会通过分层的“思维链”提示(hierarchical chain-of-thought)输入到大语言模型(LLM),以便对场景上下文进行结构化理解。作者将每个子图的概率分数插值到前沿点(frontiers),并选择得分最高的前沿点进行探索。通过总结 LLM 的推理过程,这一决策也是可解释的。利用场景图表示,作者进一步设计了一个“再感知”(re-perception)机制,帮助智能体通过持续的可信度判断放弃错误的目标对象。
相关工作
物体导航的方法
物体导航的方法可以分为两类:**端到端的强化学习方法 **和 显式的模块化方法 。
Q4:端到端的强化学习方法和显式的模块化方法是什么?
答:端到端的强化学习方法是智能体直接接收 相机观察到的图像(RGB-D),通过深度神经网络 隐式地将视觉输入编码 成潜在向量表示,然后直接预测智能体的 低层动作(如前进、左转、右转)。
显式的模块化方法的输入也是智能体观察到的视觉信息,先 构建语义地图 (semantic map) 或 BEV/3D 场景图,这些地图会在导航过程中动态更新,最后智能体根据语义地图,选择目标位置,再规划路径和动作。
Q5:语义地图是什么?
答:语义地图是一种 带标签的空间表示,不仅记录几何,还记录 物体的语义信息(是什么东西、在哪里)。
构建的方式:智能体首先通过 相机 / 激光雷达 / 深度传感器 感知环境,然后使用 目标检测 /语义分割模型 识别物体类别,最后把这些识别结果 **投影到地图坐标系 **里,逐步更新成一个带有类别标签的地图。
SG-Nav 也是一个基于大语言模型的零样本框架。但不同的是,作者提出 构建三维场景图 而不是语义地图,通过“分层的思维链”和“基于图的再感知”来提示大模型。这样可以更好地保留场景上下文,使得决策更加稳健。
大型预训练模型
机器人的大型预训练模型和视觉-语言模型受到了越来越多的关注,被广泛应用于具身智能的任务中,包括导航、任务规划、操控。研究发现,大规模视觉-语言模型因其能够端到端地处理图像和语言,成为解决具身智能问题的有力工具。
然而,视觉-语言模型仍然很难直接处理连续的 RGB-D 视频。为了更好地利用观测到的三维场景,近期的导航方法会用纯文本来描述场景,并用这些文本去提示大语言模型。而 SG-Nav 则是用 场景图来表示三维场景 ,这样能保留更多的上下文信息。 “分层思维链” 和 “基于图的再感知” 方法,也能更好地发挥大语言模型在物体导航中的潜力。
在线三维场景图构建
分层三维场景图
一个三维场景图通过节点和它们之间的边来描述场景。作者定义了三类节点:对象(object)、组(group) 和 房间(room),用不同的粒度来表示不同层次的场景。
- 组节点表示一组相关的对象,例如一张餐桌和周围的椅子,或是电视和电视柜。
- 边可以存在于任意一对节点之间。
- 如果两个节点处于不同层级(如椅子和客厅),边表示从属关系(即椅子属于这个客厅)。
- 如果两个节点处于同一层级,边表示它们的关系,可以是空间关系(如“在……上面”),也可以是功能关系(如电视和与之相对的沙发)。
增量式更新与剪枝
由于环境中有许多物体,它们之间的关系也很复杂,因此一次性构建整个场景图会非常耗时。为了实现实时在线构建,作者提出了一种 **跨帧增量更新 **的方法。也就是说,在每个时间步 ,我们从 RGB-D 观测中注册新的节点 ,并将这些节点与前一帧的场景图 相连接,从而得到新的场景图 。
Q6:跨帧是什么?
答:跨帧就是指利用多帧图像之间的时间连续性,把不同时间点得到的信息结合起来,而不是每帧单独处理。
对于 对象节点 (object nodes),采用 开放词汇的三维实例分割方法 来获取 3D 实例。具体来说,在每个时间步 t,该方法会从 RGB-D 观测中检测并分割物体,同时重建环境的 三维点云。新检测到的物体会与之前 帧的物体节点进行匹配并合并。若没有匹配上,则注册为新的物体节点。每个物体节点包含一个 **语义类别 **及其 **置信度分数 **。
Q7:点云是什么?
答:点云(point cloud) 是三维空间中 大量点的集合,每个点都有三维坐标 (x,y,z),有时还会包含颜色信息 (r,g,b) 或深度信息。RGB-D 相机中,RGB 提供颜色,D(Depth)提供深度信息 → 可以生成三维点的坐标。点云是三维空间中离散的采样点集合,用于表示环境或物体的形状和位置,是机器人理解三维世界的基础。
然后,群组节点 (group nodes) 是基于截至时刻 t 的所有物体节点计算得到的。如果两个物体节点之间有一条边,并且它们的类别是相关的,那么我们就为它们注册一个群组节点。这个过程会不断迭代,直到没有新的节点可以分配到该群组为止。作者预先定义了一个类别相关性字典,由 LLM 来判断哪些类别是相关的。对于房间节点,作者采用与获取物体节点相同的范式,其中房间被视为一个实例,因此我们可以用房间类型来提示开放词汇的三维实例分割模型。
作者还设计了不同的策略来构建不同层级节点之间的边。首先将高层级的节点与它们从属的低层级节点相连。例如,对于 房间-对象节点对,如果某个对象的 **实例掩码 **包含在房间的实例掩码中,我们则认为该对象属于该房间,并将其相连。对于 房间-组节点对,如果该组中的所有对象都属于这个房间,我们则将它们连接起来。由于组节点本身是基于对象节点注册的,因此我们不额外连接组节点和对象节点。
Q8:实例掩码是什么?
答:在计算机视觉里,掩码(mask)就是用来标记图像中某些区域的二值图像(0 表示背景,1 表示目标区域)。实例掩码(instance mask)指的是对图像中每一个独立物体实例 的像素进行标记,而不仅仅是类别。例如,会分别标记“椅子1”和“椅子2”,每个物体都有独立掩码。
接着,我们连接相关的对象节点以构建同层级的边。注意,组节点和房间节点之间没有同层级的边。对于 时刻新注册的对象节点,我们首先将它们与所有对象节点密集连接,接着进行剪枝以去除关联性不强的边。我们将新注册的 个节点与之前的 个节点进行组合,形成 条边。对于每条边,我们可以通过提示LLM来推断它们之间的关系。然而,遍历所有条边并为每条边提示LLM的计算复杂度是 。为了加速这一密集连接过程,作者提出了一种新的提示格式,使得 LLM 能够一次性生成所有节点对之间的关系,将计算成本降低为 ,具体的prompt设计和理论推导可以参考原文。
作者进一步对密集连接的边进行剪枝,以使三维场景图更加精确。新生成的关系分为两类:**长距离关系 **和 短距离关系。划分依据是 RGB-D 图像中是否同时包含两个相连的对象。如果同时包含两个对象,则该边为短距离边。对于这种情况,我们可以将 RGB 图像输入到像 LLaVA 等视觉语言模型(VLM)中,询问该关系是否存在,不存在的关系将被剪枝。否则,该边为长距离边。作者设计了两个标准来验证长距离边的合理性:(1)连接两个对象的线不被阻挡且与房间的墙壁平行;(2)这两个对象节点属于同一个房间节点。只有同时满足这两个标准的边才会被保留。
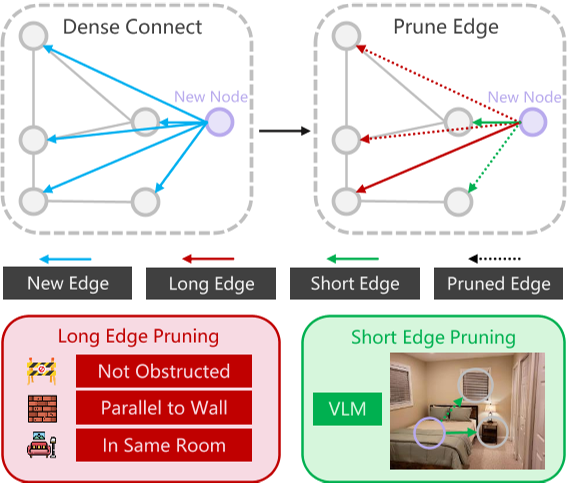
图3:边的增量生成。作者通过高效地提示大语言模型(LLM),将新注册的节点(紫色)与所有其他节点进行密集连接。我们将边分为长边和短边,并通过不同的策略剪枝信息量较低的边。
用三维场景提示LLM
分层链式思维提示
作者通过三维场景图计算每个边界的概率。在每个时刻,将场景图划分为若干子图,每个子图由一个对象节点及其所有父节点和其他直接连接的对象节点组成。对于每个子图,我们预测目标物体可能出现在该子图附近的概率。然后,第 i 个前沿的概率可以通过以下公式计算得到:
其中, 是子图的总数, 是第 个边界的中心与第 $ j$ 个子图的中心对象节点之间的距离。为了使分数预测准确且可解释,作者提出了一种分层链式思维的方法来提示 LLM,该方法充分利用了子图中的结构信息。
对于每个子图,首先提示 LLM:“预测 [object] 与 [goal] 之间最可能的距离”,其中 [object] 表示中心物体节点的类别。
然后我们提示 LLM 提出与导航目标相关的问题,提示为:“针对 [object] 和 [goal] 提出预测它们距离的问题”。
在获得关于目标的问题后,我们提示 LLM 根据子图的信息回答这些问题,提示为:“给定子图的 [nodes] 和 [edges],回答上述问题”。
因此,从这些答案中可以获得推断目标位置所需的所有信息。最后,我们提示 LLM 总结对话并预测 P,提示为:“基于上述对话,确定该子图与 [goal] 的最可能距离”。
概率 可以通过取输出距离的倒数简单计算得到。LLM 还会总结与所选前沿最近的 3 个子图的分析过程,以解释决策的原因。
利用层次化思维链,让 LLM 逐步推理子图到目标的距离,同时生成可解释的概率,为零样本导航提供可靠决策依据。
基于图的重感知机制
传统的目标巡航框架没有考虑感知错误。一旦机器人检测到错误的目标物体,它将 不再探索或感知环境,而是直接巡航到该物体。
为了解决这个问题,作者增强了现有的目标巡航框架,增加了基于图的重感知机制。当机器人检测到一个目标物体时,它将靠近该物体,从多个角度观察,并累积 置信度分数。对于从这一刻起的第 次 RGB-D 观测,通过以下公式计算可信度:
其中, 是目标物体的置信度分数, 是第 个子图的中心对象节点与该物体之间的距离, 是子图对目标物体的概率预测。 用距离加权子图概率,距离越近、概率越高,贡献越大。
作者提出的重新感知机制的成功条件为:
其中, 是预定义的最大步数, 是可信度阈值,机器人需要累积达到这个阈值才能认为目标可靠如果成功。这个公式的意思是机器人 累积每次观测的可信度分数,一旦达到阈值就停止重新感知并确认目标;否则超过最大步数仍未达到阈值,就放弃该物体。
实验结果
作者在 Matterport3D,HM3D,RoboTHOR 上开展实验,取得了最先进的零样本性能,结果如下:
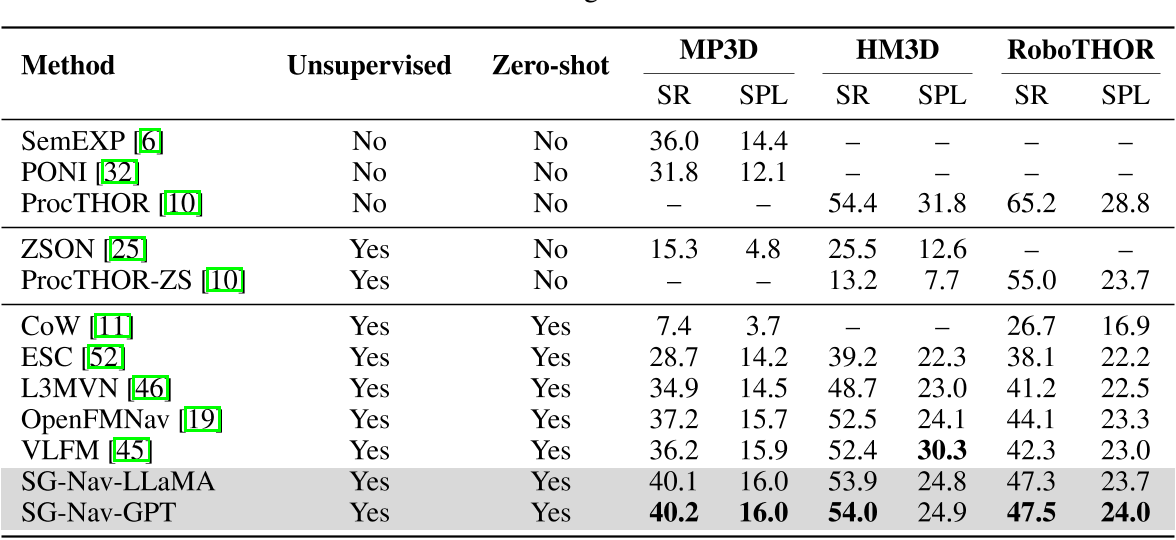
表1:在 MP3D、HM3D 和 RoboTHOR 上的目标对象导航结果。作者比较了不同设置下各最先进方法的成功率(SR)和路径效率(SPL)。
MP3D 是一个大规模 3D 场景数据集,被用于 Habitat ObjectNav 挑战。我们在验证集上测试 SG-Nav,其中包含 11 个室内场景、21 个目标物体类别和 2195 个目标物体导航任务。
HM3D 被用于 Habitat 2022 ObjectNav 挑战,包含 20 个验证环境中的 2000 个验证任务,涉及 6 个目标物体类别。
RoboTHOR 被用于 RoboTHOR 2020 和 2021 ObjectNav 挑战,包含 15 个验证环境中的 1800 个验证任务,涉及 12 个目标物体类别
评价指标
作者报告了三种指标,包括成功率(SR)、按路径长度加权的成功率(SPL)和 SoftSPL。
- SR 是目标物体导航任务的核心指标,表示成功导航任务的成功率。
- SPL 衡量智能体找到最优路径的能力。如果成功,计算公式为
- SoftSPL 衡量智能体的导航进展和导航效率。
实现细节
- 设置最大导航步数为 500。
- 智能体的最远和最近感知距离分别为 10m 和 1.5m。
- 每一步的移动距离为 0.25m,每次旋转角度为 30°。
- 智能体的摄像头高度为 0.90m,视角为水平。
- 摄像头输出分辨率为 640 × 480 的 RGB-D 图像。
- 维护一张 800 × 800 的二维占据栅格图(occupancy map),分辨率为 0.05m,可表示 40m × 40m 的大规模场景。
- 参数设置为 ,。
- 在短边验证中,采用 LLaVA-1.6 (Mistral-7B) 作为视觉-语言模型(VLM)进行判别。
- 在 SG-Nav 中,选择 LLaMA-7B 和 GPT-4-0613 作为大语言模型(LLM),分别记为 SG-Nav-LLaMA 和 SG-Nav-GPT。
消融实验
Q9:什么是消融实验?
答:消融实验就是把模型中的某些模块/组件有意识地“去掉”或“替换”,然后观察性能的变化,从而判断这些模块对最终效果的作用大小。

表2:三维场景图(SG)和再感知机制(RP)的效果。

表3和表4:表3是房间节点和组节点对实验的影响,表4是不同类型边对实验的影响。
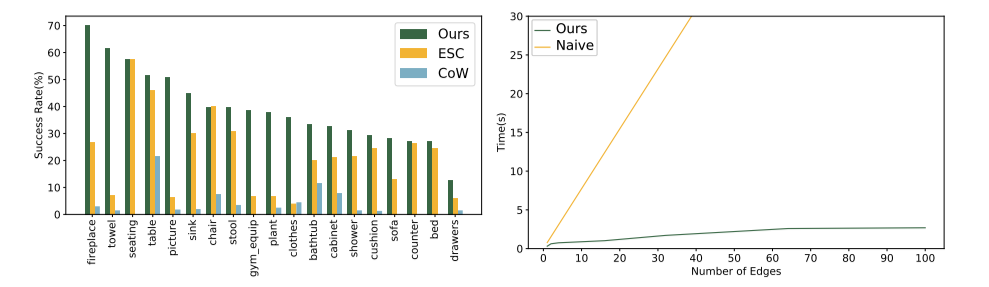
图4和图5:图4是 MP3D 上的每个类别SR,图5是连接 n 条边的时间开销。

表5:CoT提示对MP3D数据集的影响。
消融实验主要验证了 SG-Nav 中各个模块的作用:
- 场景图和再感知。 在表2中,比较了场景图(SG)和再感知(RP)的设计选择。没有 RP 时,一旦检测器找到目标,SG-Nav 就会移动到目标,即使该目标是误检。由于场景的复杂性,检测器出现错误是常见的,这会导致不可逆的导航。如果进一步移除整个SG,作者的框架将退化为随机探索模型。智能体会随机选择前沿区域,导致在所有数据集上的性能显著下降。
- 房间节点和组节点。 如表3所示,通过消融组节点和房间节点的设计来比较不同场景图架构的性能。移除房间或组节点及与其连接的边,从而得到4种不同的场景图架构。在MP3D数据集上,移除房间节点和组节点分别导致 和 的SR下降。观察到组节点比房间节点更重要,这是因为组节点能将多个物体聚合成一个整体,从而减少冗余信息和场景图的复杂性。
- 场景图构建的效率。 图5展示了作者提出的高效基于提示的方法与朴素的 $O(m(m+n)) $ 方法在生成密集连接新边时的速度对比。朴素方法的时间消耗与边的数量呈线性关系,而作者的高效提示方法显著降低了计算复杂度。
- 边的影响。 在表4中,作者研究了不同类型边的重要性。结果验证了边在作者的框架中起到重要作用,它帮助分层链式思维更好地利用环境中包含的结构信息。
- CoT 的影响。 在表5中,作者展示了 CoT 提示的重要性。“文本提示”是指直接将3D场景图转换为文本并提示LLM;“文本分别提示”是指将节点和边分别转换为文本。另外,作者移除了层之间的边,以进一步验证分层图结构的必要性。实验结果表明,作者的CoT提示能够有效地利用3D场景图中包含的结构信息。
定性分析
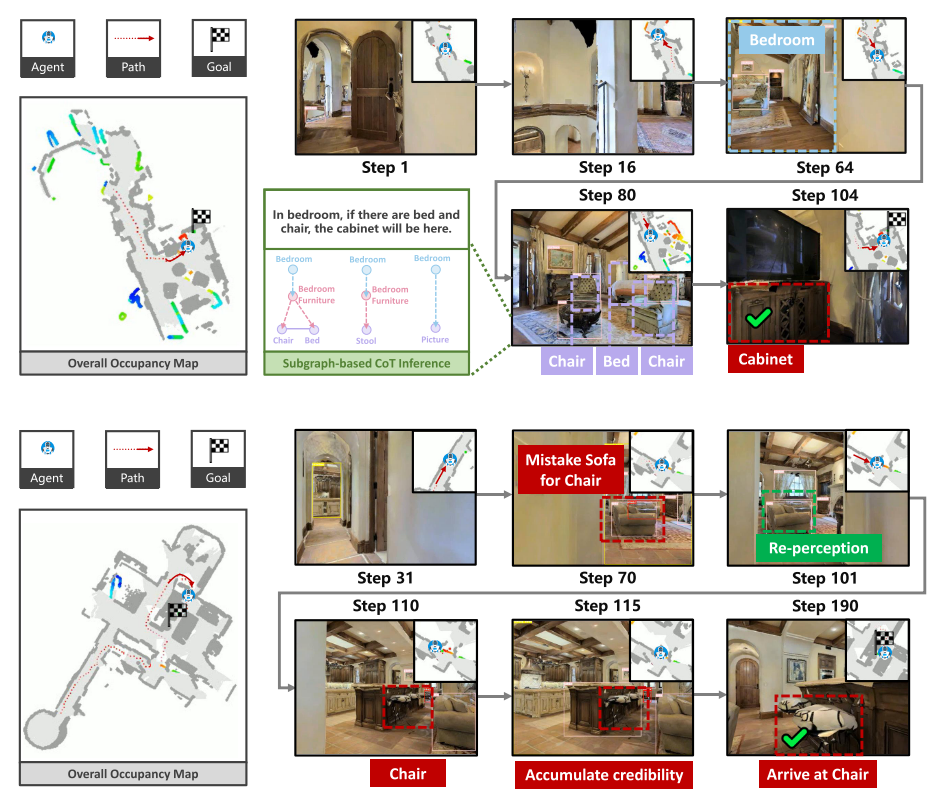
图6:导航过程可视化
图6视化了 SG-Nav 的导航过程。 上面的例子表明,SG-Nav 能够根据最接近所选边界的3个子图来解释其决策的原因。 下例表明,SG-Nav 可以积累检测到的目标物体的可信度,并利用它来判断目标的真实性,有效地纠正了感知误差。
总结
在本文中,作者提出了 SG-Nav,一种基于零样本(zero-shot)的目标对象导航框架,该框架通过场景图(scene graph)提示大语言模型(LLM)来推断目标对象的位置。首先在线构建分层的三维场景图,以保留环境中的丰富上下文信息。为了加快场景图的构建,作者又提出了一种增量更新与剪枝策略。在每一步中,作者将场景图划分为若干子图,并使用分层链式思维(hierarchical chain-of-thought)提示 LLM,输出每个子图的概率分数。接着,通过简单插值可以获得每个前沿(frontier)的分数,这一过程也具有可解释性。利用图结构表示,作者进一步设计了 再感知机制(re-perception mechanism),赋予 SG-Nav 放弃错误正例目标对象、纠正感知错误的能力。大量实验在三个数据集上验证了 SG-Nav 的优异性能以及作者设计方法的有效性。
潜在的局限性
尽管性能优异,SG-Nav 仍存在一些局限性:
- SG-Nav 依赖于在线 3D 实例分割方法来构建场景图。目前作者采用 2D 视觉-语言模型和视觉基础模型对每帧进行分割,并将不同帧的掩码进行合并,这种方法既不是端到端,也不具备真正的 3D 感知能力。一个更强的在线 3D 实例分割模型将进一步提升 SG-Nav 的性能。
- SG-Nav 目前仅能处理目标对象导航任务。然而,由于 LLM 强大的零样本泛化能力以及 3D 场景图中包含的丰富上下文信息,作者相信 SG-Nav 可以进一步扩展到更多任务,例如图像目标导航(image-goal navigation)和视觉-语言导航(vision-and-language navigation)。
