
ViNT
ViNT: A Foundation Model for Visual Navigation
摘要
通用预训练模型(“基础模型”,foundation models)使研究人员能够在远小于从零开始训练所需规模的数据集上,为具体的机器学习问题构建具有良好泛化能力的解决方案。这类模型通常在规模庞大且多样化、带有弱监督的大型数据集上进行训练,其所消耗的训练数据量远超任何单一的下游应用所能提供的数据规模。
强监督 → 精确但小规模 → 专用模型 弱监督 → 嘈杂但大规模 → 泛化模型(foundation model)
本文提出了视觉导航 Transformer(Visual Navigation Transformer,ViNT),一种旨在将通用预训练模型的成功经验引入基于视觉的机器人导航领域的基础模型。ViNT 采用一种通用的目标到达(goal-reaching)训练目标,该目标可与任意导航数据集配合使用,并基于灵活的 Transformer 架构来学习导航可供性(navigational affordances),从而实现对多种下游导航任务的高效适配。
下游导航任务:模型最终被使用的场景。通用模型经过一系列的微调或者改造来适配一个新的导航任务。
ViNT 在多个现有导航数据集上进行了训练,这些数据集涵盖了来自不同机器人平台的数百小时机器人导航数据。实验结果表明,ViNT 能够产生正迁移(positive transfer),其性能优于仅在更窄数据集上训练的专用模型。进一步地,ViNT 可结合基于扩散模型的目标提议机制以探索未知环境,并在引入长程启发式策略后解决公里级尺度的导航问题。
正迁移:模型在一个或多个任务/数据集上学到的知识,能够帮助它在新的任务(下游任务)上取得“比不迁移更好”的性能。
此外,ViNT 还可以通过一种受 prompt-tuning 启发的方法适配新的任务定义:即用另一种任务模态(例如 GPS 航点或逐步转向指令)的编码替换原有的目标编码器,并将其嵌入到同一目标 token 空间中。上述灵活性及其对多样化下游问题域的适应能力,使 ViNT 成为一种面向移动机器人领域的有效基础模型。
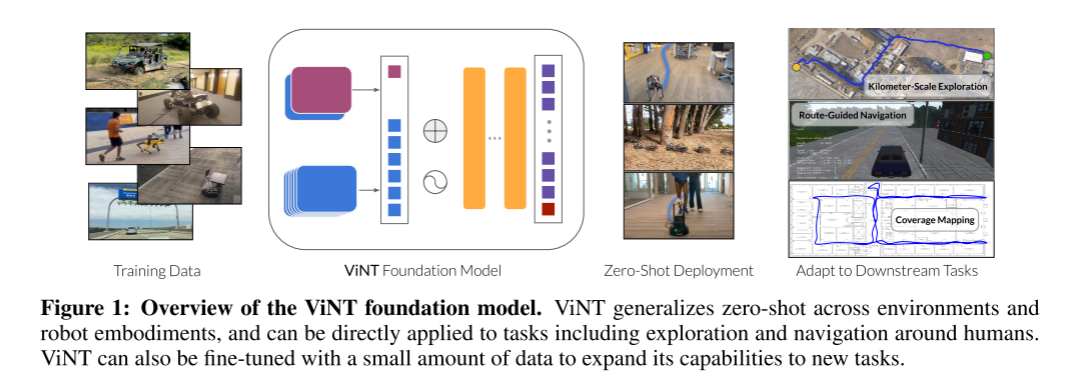
1. 引言
近年来,机器学习方法通过利用互联网规模的数据训练通用的“基础模型”(foundation models),并借助零样本迁移(zero-shot transfer)、提示调优(prompt-tuning)或在目标数据上的微调(fine-tuning)来适配新任务,在自然语言处理、视觉感知以及其他领域中取得了广泛成功。
零样本迁移:啥都不改动,直接用,完全依赖通用能力。
提示调优:不改动模型主体,只改输入,冻结参数或者训练极少量的额外参数。
微调:更新部分或全部参数,原模型基础上,用新任务数据再训练一小会儿。
尽管这一范式在多个领域表现出色,但由于机器人领域在环境、平台和应用形式上的高度多样性,其在机器人中的应用仍然面临显著挑战。本文提出了这样一个问题:一个面向移动机器人的基础模型应当具备哪些能力?
在本文中,我们将机器人基础模型(robot foundation model)定义为一种预训练模型,其应当满足以下两点:
能够在新的、具有实际价值的场景中以零样本方式直接部署(例如不同的传感器、机器人形态、环境等)
能够根据需求适配任意给定的下游任务(例如不同的目标函数、目标指定方式或行为模式等)
基于上述目标,我们提出了视觉导航 Transformer(Visual Navigation Transformer,ViNT):一种具备强零样本泛化能力、支持跨机器人形态(cross-embodiment)的视觉导航基础模型。我们通过以相机图像指定目标的目标到达任务对 ViNT 进行训练,该训练目标具有高度通用性,几乎可应用于任何移动机器人数据集。
此外,我们提出了一种新的视觉导航探索算法,利用扩散模型(diffusion model)生成短视距目标(short-horizon goals),并证明该方法能够使 ViNT 在未知环境中进行有效导航。实验表明,ViNT 能够在零样本条件下控制新的机器人,探索此前未见过的环境,执行室内建图任务,并在无需人工干预的情况下完成公里级尺度的室外导航。
进一步地,ViNT 可以仅使用少量数据进行微调,即可适配新的任务目标指定模态——例如 GPS 航点或高层次路径指令——从而使其成为支持多种导航应用的基础模型。最后,我们对 ViNT 所展现出的一些涌现行为(emergent behaviors)进行了定性分析,例如其隐式偏好以及对动态行人的绕行行为。
模型权重以及训练与部署代码将发布于项目主页。
2. 相关工作
在移动机器人应用场景下,由于机器人在动力学特性以及相机配置(例如焦距、视场角和外参)方面存在显著差异,现有方法往往依赖于以下两种途径之一:
仅在规模较小的真实世界数据集上进行学习,而这些数据通常只代表单一机器人平台。
依赖仿真环境,并结合成对的机器人与环境模型,将在仿真中学到的策略迁移到真实世界中。
与此不同,本文遵循一种从多种不同真实机器人系统所采集的数据中学习导航行为的研究范式,并将重点放在训练一种基础模型上,使其能够在零样本条件下或仅使用少量数据,适配多种下游任务。
3. ViNT 模型
我们的模型以图像目标导航(image-goal navigation)为训练任务,从而学习通用的导航能力。在图像目标导航任务中,机器人需要导航至一个由图像观测 指定的子目标(即机器人在目标位置处的视觉观测)。 与 PointGoal 导航、GPS 导航或语义目标等其他目标指定方式不同,图像目标导航在训练时几乎不需要任何额外假设:只要数据中包含视频序列和动作信息即可,而不需要真实位姿、语义标注或其他元数据。这使得模型能够在来自多种机器人、规模大且多样的数据集上进行训练,从而促进更广泛的泛化能力。
PointGoal导航:用一个相对位姿点作为目标,比如“目标在前方 3 米,左偏 20”。
GPS导航:用全球坐标系下的位置作为目标,比如“走到经纬度 (lat, lon) = (…, …)”。
语义目标导航:用语义标签作为目标,比如“走到厨房”。
3.1 输入
ViNT 的输入包括当前及过去的视觉观测 以及一个子目标图像 ,并预测两项输出:
到达子目标所需的时间步数(即动力学距离,dynamical distance)。
一段长度为 的、指向子目标的未来动作序列。
ViNT 是一个包含约 3100 万参数的模型,基于 Transformer 架构设计,重点优化了以下两个方面:
- 在资源受限的机器人平台上实现快速、高效的推理
- 具备通过提示或微调适配下游任务的能力
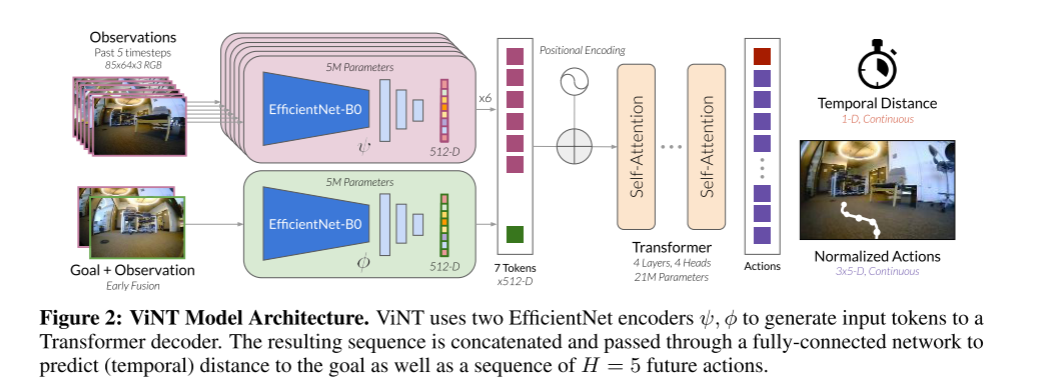
3.2 Token化(Tokenization)
ViNT 架构首先将输入转化为维度为 的嵌入表示。
模型分别对当前观测和过去的 帧观测进行编码。每一帧图像通过 EfficientNet-B0 编码器处理,输入大小为 ,并从最后一层卷积中提取并展平成特征向量:。
EfficientNet-B0:是一种轻量、高效的卷积神经网络(CNN),常被用作图像特征提取器(encoder)。
在 ViNT 中,它的作用是:把一张原始 RGB 图像,变成一个高维但紧凑的特征向量,供 Transformer 使用。
它和 ResNet、VGG 是同一类东西。
EfficientNet 不是一个模型,而是一整个模型家族:
名称 大小 计算量 适合场景 B0 最小 最轻 嵌入式 / 机器人 / 实时 B1–B3 中等 ↑ 普通 GPU B4–B7 很大 很重 服务器 / 离线训练
3.3 目标融合(Goal Fusion)
实验发现,若直接使用 EfficientNet 编码目标图像 ,模型往往会忽略目标信息,导致性能较差。我们推测,在基于图像的目标到达任务中,有效的特征通常是相对特征,即描述当前观测与目标之间差异的特征,而不是目标图像的绝对表示。
因此,我们采用一个单独的目标融合编码器 ,用于联合编码当前观测与目标观测。具体做法是:在通道维度上将两张图像进行拼接,输入到第二个 EfficientNet-B0 编码器中,并将输出展平成目标 token。
3.4 Transformer 主干网络
来自 个观测和目标 token 的嵌入与位置编码相结合后,被输入到 Transformer 主干网络中。
ViNT 使用的是 decoder-only Transformer 架构,其具体配置如下:
- Transformer 层数:
- 多头注意力头数:
- 前馈网络隐藏层维度:
3.5 训练目标(Training Objective)
在训练过程中,我们从数据集 中采样一个轨迹批次 。随后,选择连续的 帧作为时间上下文 ,并从未来的观测中随机选取一个观测作为子目标:
对应的未来 步动作序列:,以及距离 被作为监督信号。
模型通过如下的最大似然目标进行训练:
其中:
- $ ϕ,ψ,f$ 分别表示目标编码器、观测编码器和 Transformer
- 用于平衡动作预测与距离预测两项损失
符号 含义 EfficientNet 提取的图像特征 当前 + 过去 P 帧的特征 当前图像 + 目标图像的融合特征 Transformer 主干网络
是在模型当前理解下,真实走过的动作序列概率有多大
是模型能不能判断“离目标还剩多少步”
是一个权重:
- 大 → 更强调“距离感”
- 小 → 更强调“动作模仿”
所以这个公式的意思是:
L = E[ log p(动作 | 输入) + λ log p(距离 | 输入) ]通过这个公式来计算loss。
3.6 与机器人形态无关的动作空间
为了在不同尺寸、速度和动力学特性的机器人之间训练统一模型,ViNT 采用了一种与机器人形态无关的动作空间表示。模型使用相对航点(relative waypoints)作为动作 ,并根据机器人的最大速度对航点进行归一化,以消除不同机器人之间的尺度差异。
在部署阶段,使用机器人专属的低层控制器对航点进行反归一化,并通过低层控制完成航点跟踪。
3.7 训练数据
ViNT 使用一个大规模、异构的真实世界导航数据集进行训练。该数据集包含超过 100 小时的真实机器人导航轨迹,来源于 8 种不同的机器人平台,涵盖多种环境、动力学特性、相机参数和行为模式。
3.8 部署
ViNT 可部署在任何配备机载摄像头和低层速度控制器的移动机器人平台上。在部署过程中,给定时间 的目标图像 ,模型以 4 Hz 的频率运行,并通过 PD 控制器以滚动时域(receding-horizon)的方式跟踪预测的航点序列。
4.基于 ViNT 的长时序导航(Long-Horizon Navigation with ViNT)
我们通过将 ViNT 与一种由拓扑图构成的情景记忆(episodic memory)相结合,将其应用于多个下游任务。该拓扑图为到达远距离目标提供短时序的子目标。在此前未见过的环境中,我们进一步通过引入探索性子目标提议机制来增强这一基于图的规划器,从而驱动 ViNT 主动探索新环境并发现通往目标的路径。
扩散模型负责“想去哪”,ViNT 负责“能不能去 + 怎么去”,图搜索负责“先去哪”。
整个流程是这样的:
当前观察
扩散模型生成 subgoals
ViNT 做空间 grounding
用目标导向启发式函数 打分
A*-like planner 选最优 subgoal
加入图
ViNT 执行动作
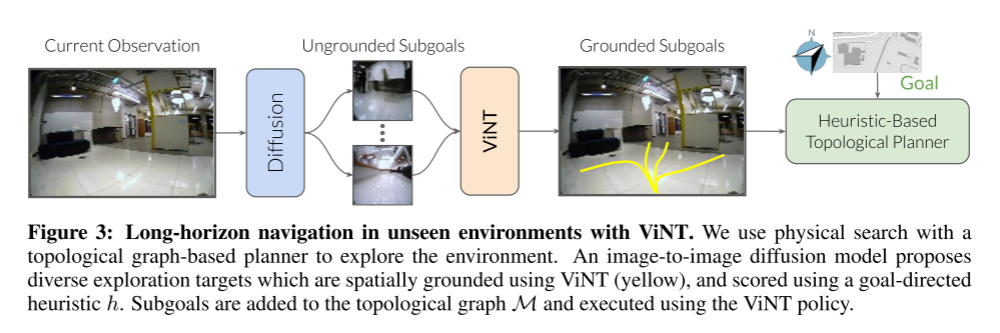
4.1 高层规划与探索(High-Level Planning and Exploration)
假设我们已经有了一组可供 ViNT 用来规划的子目标候选。
先不管子目标怎么来的,这边将怎么用“子目标”
我们将这些子目标候选融入一个面向新环境的目标导向探索框架中。在该框架下,用户提供一个高层目标 ,其距离可以是任意远的。
然后在线构建一个拓扑图 作为情景记忆,其中:
- 每个节点对应一个独立的子目标观测。
- 当机器人实际走过一条路径,或模型预测某个子目标可以从另一节点到达时,在两节点之间添加边。
于是目标导向探索被表述为一个搜索问题:机器人在搜索目标的过程中逐步构建拓扑图 。为了引导搜索朝向目标,机器人使用一个目标导向启发式函数 对每个子目标候选进行评分,其中 表示额外的上下文信息,例如楼层平面图或卫星图像。该启发式函数可以是几何形式的(如欧氏距离),也可以是学习得到的。
:当前观察
:某个子目标
:最终目标
:当前记忆图
:额外上下文(如卫星图)
4.2 基于扩散模型的子目标生成(Subgoal Generation with Diffusion)
如何去寻找subgoals呢?从本质上看,这相当于从一个高维、多模态的 RGB 图像分布中进行采样。
为此,我们在 ViNT 的训练数据上训练了一个条件生成模型:,输入的是当前观察,输出可能的未来观察(subgoals)。这是一种图像到图像的扩散模型,该类生成模型非常适合在 RGB 图像等高维空间中生成多样化样本。训练方法是使用 ViNT 数据集中随机采样的未来观测进行训练,并在推理阶段从模型中采样 个子目标候选 。
扩散模型是什么:是一类通过逐步去噪来生成数据的生成模型,能从当前视角,幻想出多种合理未来画面。
然而,这些子目标生成结果本身并未进行空间层面的约束,即它们并不直接包含与当前观测 之间的可执行关系。为此,我们使用 ViNT 对这些候选进行空间约束,通过预测时间距离 以及对应的动作序列 ,从而得到一组空间上有意义的子目标。
ViNT进行grounding:把扩散模型生成的目标图像转化为可执行的空间与动作关系。
如下图:候选方案以黄色显示,最佳动作对应的最优候选方案以蓝色标记。

5.ViNT 作为下游任务(Downstream Tasks)的基础模型
除了作为一个以图像目标为条件的核心导航模型之外,我们进一步表明,ViNT 所学习到的强导航先验(navigational priors)可以通过对模型的部分或全部进行微调,适配到多种下游任务中,而不仅仅局限于图像目标导航。
5.1 全模型微调(Full model fine-tuning)
尽管 ViNT 在面对新的环境和机器人平台时已经表现出很强的零样本泛化能力(zero-shot generalization),但我们仍然可以通过在任务相关数据上、使用相同的训练目标对整个模型进行微调,从而进一步提升其在具体任务上的性能。 这种方式使得 ViNT 能够快速学习新的技能,并逐步形成一个持续改进的模型。在实际实验中,ViNT 仅需大约 1 小时的导航数据,就可以掌握新的环境和新的机器人本体,将原模型中学到的能力有效迁移到新的设置中,而无需从头开始重新训练。
5.2 适配新的目标模态(Adapting to new modalities)
目标模态 = 目标是“用什么形式给模型的”
如果目标不是一张图,而是 GPS、坐标、路线指令,ViNT 还能不能用?
ViNT 的 Transformer 期望输入的是一组 token embedding:
- 视觉 token(来自 EfficientNet)
- goal token(同样是 embedding)
如何适配新的目标模态?
不让 ViNT 学新任务,而是把新目标“翻译”成 ViNT 已经会用的 goal token。
所以,原本是 goal token = $φ(o_t, o_s) $,要想办法实现 goal token = $ϕ̃(σ) $ ,需要一个小型的神经网络实现来和原 goal token 同维度、同语义空间。
这是 ViNT 能被称为 foundation model 的关键证据。
6. 真实世界评估(Real-world Evaluation)
部署平台:5 种机器人(无人机、四足机器人、轮式机器人等)
关键点:
- 多个平台 未出现在训练数据中
- 无传感器/控制统一(真实世界异构)
回答 4 个问题:
- Q1:能否在未知环境中探索?
- Q2:能否零样本泛化到新机器人?
- Q3:少量数据微调是否有效?
- Q4:能否适配新的任务/目标形式?
6.1 导航与探索性能(Q1)
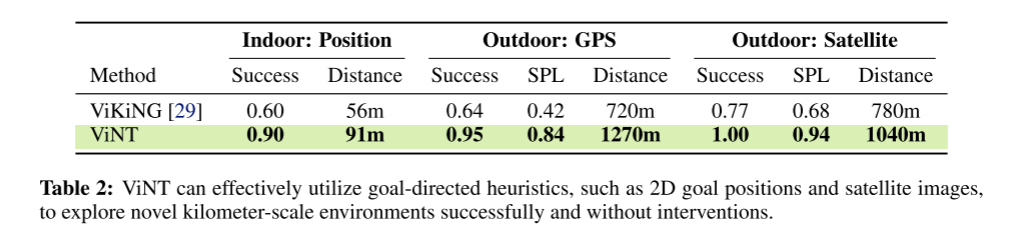
任务类型:
- 覆盖式探索:不知道目标在哪,尽可能探索环境
- 引导式探索:有 GPS / 卫星图 / 位置等线索
关键结论:
- 端到端方法:容易卡住、探索不充分
- ViNT(图搜索 + 扩散子目标):
- 探索效率更高
- 路径更直接
- 碰撞更少
- 原因:
- 扩散模型生成多样子目标
- 图搜索显式建模“覆盖率”
结论:ViNT 在未知环境中具备强探索能力
6.2 零样本泛化到新机器人(Q2)
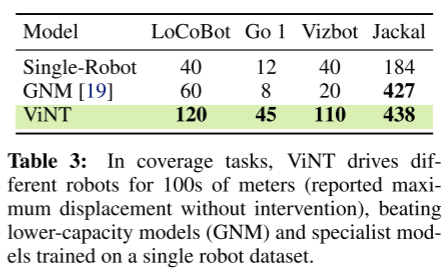
实验方式:
- 不微调
- 直接将同一个 ViNT policy 部署到不同机器人
关键发现:
- 成功控制 未见过的机器人(如 Go1 四足)
- 多机器人联合训练 > 单机器人专用模型
- ViNT > 小模型(如 GNM)
重要现象:正迁移
- 在“见过的机器人”上
- ViNT 甚至 超过只用该机器人数据训练的专家模型
这是 foundation model 的标志性特征
6.3 少样本微调能力(Q3)
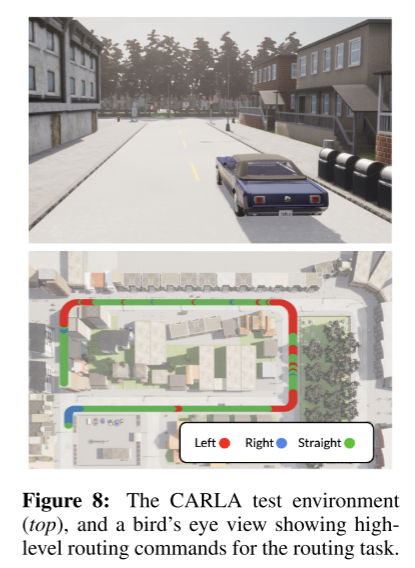
设置:
- 微调整个 ViNT
- 数据量:1–5 小时
- 场景:CARLA 自动驾驶(与真实数据分布差异很大)
结果:
- < 1 小时数据即可显著提升性能
- 能学会:
- 车道保持
- 平滑转弯等新语义行为
结论:ViNT 具备强大的少样本适应能力
6.4 适配下游任务与新目标模态(Q4)
新任务形式:
- GPS waypoint 序列
- 类 Google Maps 的转向指令(左/右/直)
方法:
- 不改主模型
- 用 soft prompt(小网络)
- 将新模态映射到 ViNT 的 goal token 空间
对比结果:
- ImageNet / VC-1 特征:不够
- GNM:适配能力弱
- ViNT:效果最好
结论:ViNT 能作为通用导航基础模型服务下游任务
6.5 涌现行为(非直接训练得到)
观察到的涌现能力:
- 隐式避障:即使目标无意义也能安全行动
- 隐式偏好:
- 室外走路
- 室内走廊居中
- 对动态行人鲁棒
说明 ViNT 学到的是:“如何在世界中合理移动”的先验,而不只是模仿轨迹。
