
travelUAV
面向真实环境的无人机视觉语言导航,平台、基准与方法
摘要
VLN的大多数研究都集中在地面上,而基于无人机的VLN仍然相对未被充分探索。目前,无人机视觉语言导航主要采用基于地面的VLN设置,依赖于预定义的离散动作空间,而忽略了智能体运动动力学的内在差异以及地面和空中环境之间导航任务的复杂性。为了解决这些差异和挑战,作者从三个角度提出了解决方案:平台、基准和方法论。
平台:提出了开放无人机平台OpenUAV,该平台具有多样化的环境,逼真的飞行控制和广泛的算法支持。同时进一步在该平台上构建了一个由大约12k个轨迹组成的面向目标的VLN数据集,作为专门为现实无人机VLN任务设计的第一个数据集。
基准:提出了一种UAV-Need-Help的辅助制导无人机目标搜索基准,该基准提供了不同级别的制导信息,以帮助无人机更好地完成现实VLN任务。
方法:提出了一种无人机导航LLM,在给定多视图图像、任务描述和辅助指令的情况下,利用MLLM的多模态理解能力来联合处理视觉和文本信息,并执行分层轨迹生成。
作者方法的评估结果明显优于基线模型,但结果与人工操作人员的结果之间仍存在相当大的差距,这突显了UAV-Need-Help任务所带来的挑战。
引言
地面基准和UAV的差异与挑战
智能体运动的动力学不匹配
地面智能体通常沿着水平面移动,这使得使用水平移动和旋转等离散动作来规划导航变得很简单。相比之下,无人机可以在三维空间自由操作。如图1所示,传统方法试图使用固定的动作集来定义UAV的运动,这些动作集包含了向上、向下和水平运动等基本方向。这些方法过于简化UAV控制,无法捕捉真实的飞行动力学,因为无人机经常执行像俯仰,潜水和滚动同时实现空间运动的机动。UAV轨迹本质上是连续的,很难分解成离散的动作,当应用这种简化时,导致不现实的导航。
导航任务复杂度的差异
无人机经常在各种户外开放环境中运行,这些环境中的导航路径通常又长又复杂。而地面智能体使用定义良好的目标物体描述进行导航。无人机由于具有高机动性,必须处理受阻的视图和变换的视角。因此,在如此复杂、动态的场景中,仅仅依靠目标描述是不足以实现精确定位和导航的。
为了解决这些差异和相关挑战,我们提出了一个UAV仿真平台OpenUAV,一个面向目标的VLN数据集,一个新的基准无人机-需要帮助,以及一个UAV导航LLM,以创建一个更现实的UAV视觉语言导航框架,支持连续轨迹和复杂场景。
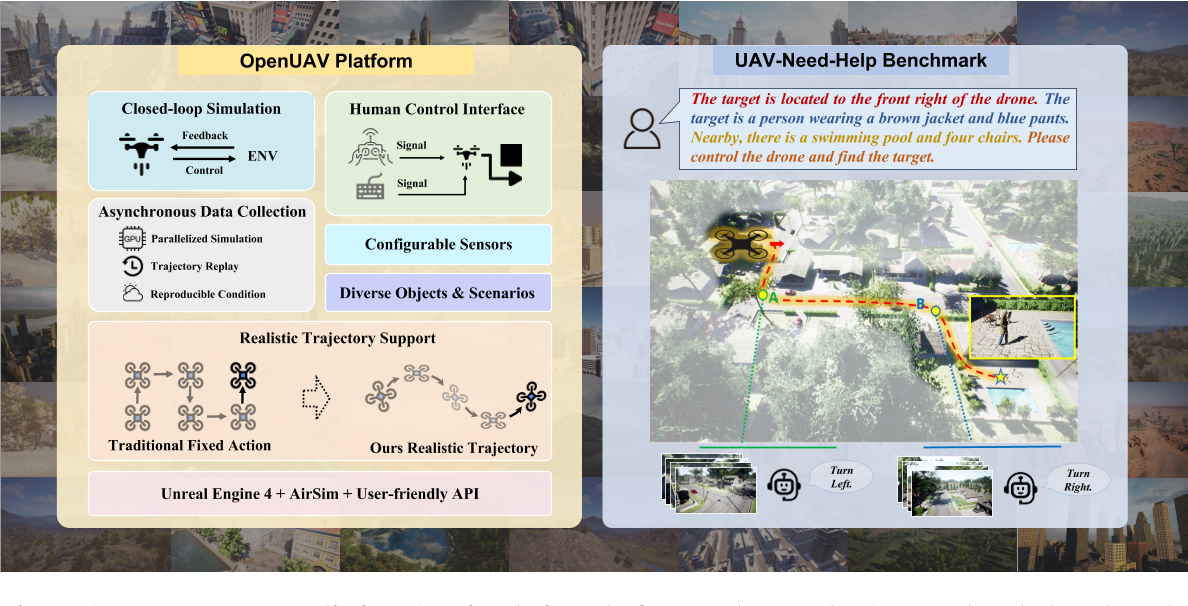 图1:提出了一个现实的无人机仿真平台和一个新的无人机-需要帮助基准
图1:提出了一个现实的无人机仿真平台和一个新的无人机-需要帮助基准
OpenUAV、UAV-Need-Help与UAV导航LLM
OpenUAV平台
为了缩小与现实UAV VLN任务的差距,一个关键的进步在于用连续的飞行轨迹取代固定的动作序列。为了促进这一点,作者引入了OpenUAV,这是一个提供逼真环境,真实飞行模拟和广泛算法支持的平台。如图1所示,我们利用UE4的逼真渲染能力,集成了22个场景和89个对象,并提供了对象放置和场景配置的api。作者集成了AirSim插件,将轨迹序列转换为具有逼真飞行动力学的连续路径,并通过遥控器或设计的api支持使用真实飞行信号的连续飞行控制。基于上述特点,作者开发了并行的真实轨迹采集框架和闭环仿真框架,为UAV任务提供全面的算法支持。
数据集构建
为了缓解VLN任务中真实UAV轨迹数据的稀缺性,作者利用OpenUAV平台的独特功能,构建了面向目标的VLN数据集,这是第一个包含6自由度(DoF)运动的真实UAV VLN数据集,准确捕捉无人机的复杂飞行动力学。人类注释员在OpenUAV上进行了连续飞行平台,在注释期间定期记录UAV状态,并异步收集附加传感器数据以获得导航轨迹。利用GPT-4生成目标描述,并随后进行手动质量检查以生成高质量的导航指令,这总共产生了大约12k个轨迹-指令对。
UAV-Need-Help基准
无人机的高机动性和复杂的空中环境对仅依靠描述指令的UAV目标搜索任务提出了重大挑战。如图1所示,作者建立了一个在特定场景下为无人机提供动作指导的助手,并根据指导程度的不同将助手分为三种类型。UAV基于初始目标描述、环境信息和来自助手的指令执行任务。
UAV导航LLM
为了提高无人机在目标搜索任务中的效率,作者提出了一种无人机导航LLM。利用MLLM的理解和决策能力,为长距离和细粒度的轨迹产生分层输出。此外,作者提出了一种基于回溯采样的数据聚合策略,以增强对环境的理解和避障能力。
相关工作
仿真平台
仿真平台是智能系统研究的关键。对于地面模拟,Habitat、Matterport3D和谷歌Street View等平台已经成为模拟真实的室内和室外场景的关键,通过改进复杂场景下的数据收集和算法评估,显著推动了研究。然而,无人机仿真平台仍处于发展的早期阶段。而一些现有的平台为无人机导航提供了基础,但它们在真实感、可扩展性和各种场景方面仍然存在局限性。xView平台仅提供不适合低空导航任务的遥感卫星图像。近年来,一些研究将UE与AirSim结合起来开发高保真成像平台。然而,这些平台要么存在渲染精度低的问题,要么缺乏对连续轨迹VLN任务的算法支持。相比之下,作者的平台提供了逼真的环境,真实的飞行模拟和广泛的算法支持,为逼真的无人机 VLN研究提供了基础。
视觉语言导航数据集
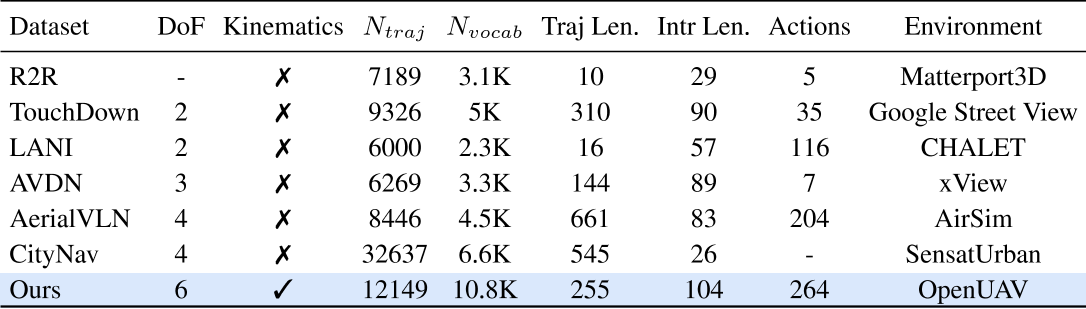
表1:代表性VLN数据集之间的比较
从室内导航开始,R2R数据集为接地VLN奠定了基础。TOUCHDOWN、LANI都采用了语言导航指令来应对户外长距离导航的挑战。超越地面级导航,AVDN收集了带有人类对话的空中导航轨迹。AerialVLN和 CityNav提出了面向无人机的 VLN,并收集了 离散的四自由度(4-DOF)无人机动作的空中轨迹数据集。在以往的数据集中,无人机轨迹通常是通过简单地修改 UAV 的位置来获取,这与真实无人机飞行存在显著差距。基于作者的平台,作者收集了一个面向目标的、逼真的 UAV VLN 数据集,其轨迹为连续的六自由度(6-DOF),以提升无人机导航任务的真实感。
基于LLM的导航智能体
基于 LLM 的方法在导航智能体的研发中取得了显著进展。LM-Nav提出了一种目标条件驱动的机器人导航方法,即使在没有语言标注数据的情况下,也能在真实的室外环境中实现稳健的泛化能力。LMDrive进一步推动了该领域的发展,提出了一种语言引导的端到端自动驾驶框架,集成了多模态传感器数据,从而在复杂的城市场景中实现高效的人机交互。一些研究利用 LLM 的零样本能力生成 UAV 导航代码,而 Lee 等则结合 LLM 对无人机目标点的坐标进行优化,验证了 LLM 在无人机导航任务中的基础能力。为了进一步拓展无人机的应用场景,作者提出了一种由分层轨迹生成模型组成的 UAV 导航 LLM,用于解决目标搜索任务。
OpenUAV仿真平台组成
如图1,OpenUAV 仿真平台是一个专注于真实 UAV 视觉语言导航(VLN)任务的完全开源平台,集成了环境构建、飞行仿真和算法支持三大模块,从而实现了全面的功能。
环境构建
多样化场景资源
提供了广泛的场景,并通过UE4实现高保真的视觉效果。整合了来自在线存储库的高质量场景和来自CARLA模拟器的城市场景,形成了具有22种不同场景的OpenUAV平台,包括城市、农村和自然景观。
定制化物体资源
具有各种各样的独立对象资产,包括人类,车辆,动物,道路标志,表格和其他适合城市和自然环境的物品。用户可以根据任务要求,使用不同的方法将物体放置在场景中。除了UE4的内置场景编辑器,还支持在运行时自动放置方法。
飞行仿真
真实 UAV 飞行控制
集成了AirSim插件,实现真实的UAV飞行模拟,实现更精确的飞行控制。平台可以利用飞行控制API来实现具有6自由度轨迹表示的基于物理的UAV机动。
可配置 UAV 传感器
支持UAV飞行期间各种传感器有效载荷的模拟,包括IMU、RGB和深度相机、激光雷达和GPS。用户可以根据具体要求添加必要的有效载荷并调整详细的传感器配置,例如修改图像分辨率以优化响应时间。
人工控制接口
平台为人类控制无人机提供了多种方法,实现了连续运动。首先,可以与PX4集成,以支持远程控制器操作。此外,开放无人机平台为无人机提供两个操作api:手动和位置模式。
算法支持
数据采集工具
实现了一种异步采集方法,首先以等时间间隔采集无人机姿态信息,然后在后台进行传感器数 据采集。
闭环仿真
该平台为无人机导航模型提供了扩展接口,允许灵活集成模型输出以控制无人机飞行,并将环境信息实时反馈给模型。此外,作者实现了一种数据集聚合方法来增强模型训练,并提出了回溯策略。当无人机遇到碰撞时,它恢复到以前的位置,并使用教师动作执行下一步,允许它从碰撞中恢复并产生更长的导航轨迹。
并行化
允许多个模拟环境并发运行,以提高数据采集和闭环评估的效率。
数据集构建
作者基于 OpenUAV 平台构建了一个面向目标的真实无人机视觉-语言导航(UAV VLN)数据集,这是首个能够准确捕捉复杂飞行动力学的 UAV VLN 任务数据集。如图2所示。
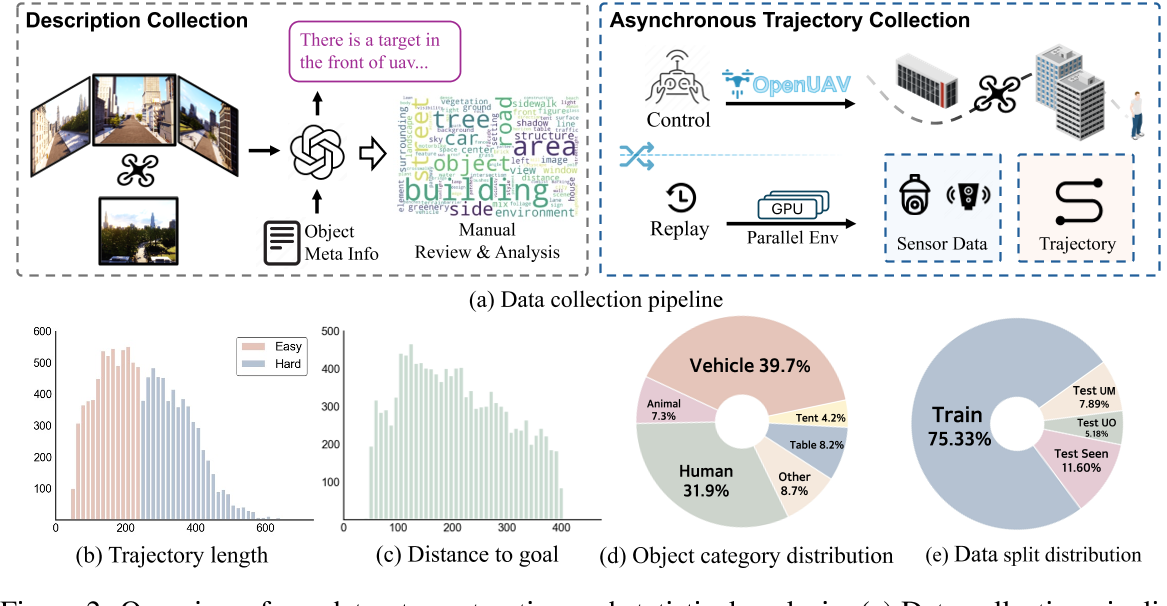
图2:数据集构建和统计分析概述
数据采集
描述采集
目标描述包含三个关键组成部分:
- 目标方向,指示目标与无人机初始位置之间的相对方位;
- 物体描述,详细说明目标的视觉特征;
- 环境信息,描述周围的空间环境。在描述采集过程中,物体可通过 OpenUAV 的物体放置接口被放置在场景的合理区域。随后,通过将摄像机置于目标上方,从五个不同视角(前、后、左、右和下方)采集图像,利用 GPT-4 生成文本描述(具体提示见附录 B)。由人工专家审核并修订生成内容,保证数据质量,剔除不准确或虚假的描述。
异步轨迹采集
在轨迹采集过程中,专家通过 OpenUAV 平台的人机控制界面,根据给定指令手动操控无人机搜索目标。为减少传感器数据存储延迟导致的操作中断,只在固定时间间隔记录无人机状态。轨迹采集完成后,传感器数据通过 OpenUAV 的并行数据采集框架获得。无人机接近目标 5 米内时轨迹记录结束,如检测到碰撞则舍弃该轨迹。最终,共获得 12,149 条有效轨迹。
数据分析
轨迹分析
如图 2 (b) 所示,UAV-Need-Help 数据集包含共计 12,149 条轨迹,其中轨迹长度少于 250 米的定义为简单任务,超过 250 米的定义为困难任务。轨迹长度的多样性确保了任务的挑战性和复杂度。图 2 (c) 显示目标距离范围从 50 米到 400 米,代表了环境的空间尺度。
描述分析
图 2 (a) 展示了最常见的描述词汇,包括建筑、树木和汽车等。这些描述为无人机提供了上下文信息,增强其通过视觉线索估计目标位置的能力,从而更准确地找到目标。图 2 (d) 表明目标物体集合包含 89 个不同类别,涵盖车辆、人类、动物及其他物体。
数据集划分
如图 2 (e) 所示,为了全面评估模型在已见环境和未见环境中的表现,并分析其对新地图和新物体的泛化能力,作者将数据集划分为四个子集:训练集(Train)、已见测试集(Test Seen)、未见地图测试集(Test Unseen Map)和未见物体测试集(Test Unseen Object)。每个测试子集又按上述标准划分为简单和困难两类。具体分布如下:
- 训练集:9152 条轨迹,涵盖 20 个场景中的 76 个物体。
- 已见测试集:1410 条轨迹,包含训练集出现过的物体和场景。
- 未见地图测试集:958 条轨迹,包含训练集中未出现的 2 个场景。
- 未见物体测试集:629 条轨迹,包含训练集中未出现的 13 个物体。
UAV-Need-Help基准测试
任务定义
形式化地讲,在每个任务回合中,无人机从初始位置和姿态 P0 开始,接收到目标描述 I,该描述包括目标方向、物体特征和周围环境。每个时间步,无人机获得当前状态 S(位置、姿态、速度),以及来自五个视角(前、左、右、后和下方)的 RGB 图像 R 和深度图 D。助理会监控无人机状态,并在需要时提供额外指令 I′,建议飞行策略。在闭环仿真中,无人机导航模型基于输入 {I,S,R,D} 预测一条 6 自由度(DoF)的轨迹序列。利用 OpenUAV 平台的飞行 API,无人机以预测的 6 DoF 姿态 {x′,y′,z′,θ′,ϕ′,ψ′}导航至每个位置,同时遵守飞行动力学并实时更新观测信息。当无人机降落至目标 20 米半径范围内时,任务视为成功。
助理机制
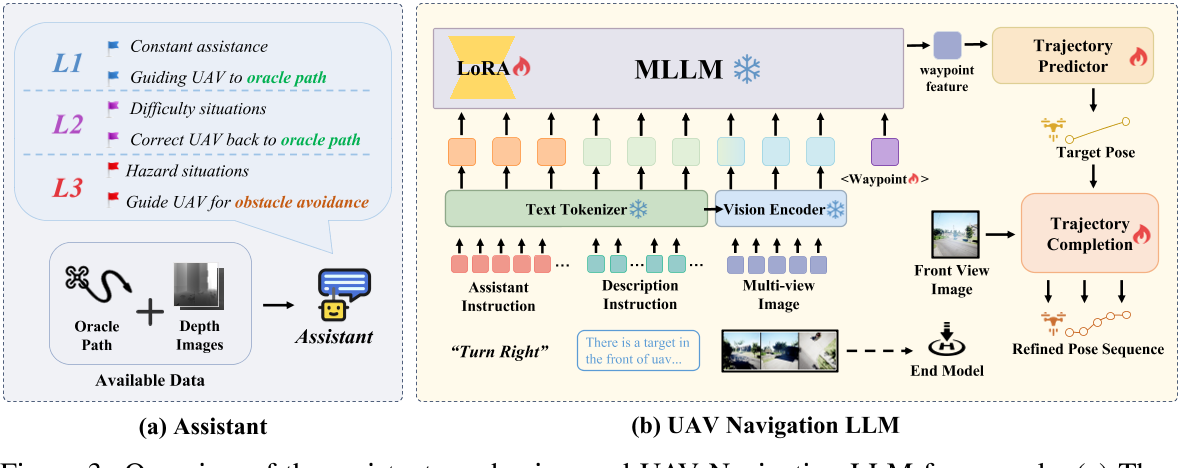
图3:助理机制和无人机导航LLM框架
如前所述,空中环境的复杂性和动态变化(视野受阻、视角不断变化)使得基础目标描述难以满足无人机目标搜索需求。因此,作者引入助理机制辅助无人机完成任务,定义了三个不同级别的助理指导,如图 3 (a) 所示:
- L1 助理:提供高频率、与真实轨迹高度一致的引导。它持续计算无人机当前位置与真实轨迹上最近点的距离,并根据无人机朝向与该点方向判断适当动作,如巡航、转向或降落。此机制保证无人机始终沿正确路径前进。
- L2 助理:当无人机遇到困难时介入,提供低频率的纠正,帮助无人机回归真实轨迹。该助理仅在通过深度图检测到碰撞风险或无人机偏离真实路径较远时激活,发出纠正指令引导无人机返回预期轨迹。
- L3 助理:仅在无人机处于危险环境时提供避障帮助。它通过深度图计算无人机当前位置与障碍物的距离,当检测到接近障碍时,发出避让指令以防止碰撞。
无人机导航大语言模型
作者首先对多模态输入进行分词,其中视觉令牌(tokens)被映射到语言空间。然后将这些令牌拼接后输入到以 Vicuna-7B 为基础模型的大语言模型(LLM)中。利用 LLM 获得的特征,一个层次化的轨迹解码器生成无人机的下一个目标姿态以及细化的轨迹序列。整体架构如图 3 (b) 所示。此外,作者设计了一种基于回溯采样的数据聚合方法,以扩充数据集,从而提升模型在复杂场景下的避障能力。
层次化轨迹生成
多模态分词
给定任务描述和助理指令,使用预训练语言分词器对两者进行分词,得到相应的令牌。对于多视角图像,采用 EVA-CLIP 模型和 Q-former 结构提取视觉特征。每张图像被转换为一组令牌,包括 1 个上下文令牌(捕捉全局特征)和 16 个内容令牌(通过网格池化提取局部细节)。最终,我们将三类令牌拼接组成多模态输入序列。
层次化轨迹解码器
高层 MLLM 轨迹解码器:使用一个可学习的轨迹令牌输入到 LLM 中,提取轨迹特征,然后通过多层感知机(MLP)解码得到目标姿态,实现基于环境数据和语言指令的轨迹规划。
细粒度路径解码器:负责生成轨迹细节并提升导航效率。它接收前视图视觉令牌和来自 MLLM 解码器处理过的姿态特征,将两者拼接后通过 MLP 输出细粒度轨迹 。为了进一步提升无人机在目标附近的着陆精度,采用了 Grounding DINO 模型进行目标检测。一旦多视角图像中识别到目标物体,导航器便启动着陆流程。
基于回溯采样的数据聚合
作者实现了 DAgger 算法模块,用于连续且真实的无人机轨迹采集。在闭环仿真中使用 DAgger 采集数据时,该模块从模型预测轨迹和教师模型提供的真实轨迹中采样,以生成视觉-语言导航任务的路径。由于无人机飞行仿真中常出现碰撞,完整且包含足够避障知识的轨迹采集较为困难。为此,提出了回溯采样机制:当无人机根据模型输出的动作导致碰撞时,系统会回退到两帧之前的状态,恢复姿态、速度等属性,然后跟随教师模型轨迹继续执行。这样可以获得更多成功的避障轨迹,提升模型的导航能力。
实验
实验设置
评估指标
采用视觉语言导航领域常用的评估指标,包括成功率(SR)、oracle 成功率(OSR)、路径长度加权成功率(SPL)和导航误差(NE)。
- 成功率(SR):衡量无人机成功到达目标的任务比例。
- oracle 成功率(OSR):衡量无人机是否到达了最优轨迹上的任意位置,即使未精确抵达最终目标。
- 路径长度加权成功率(SPL):综合评估成功率和路径效率,奖励使用较短且更优路径的导航。
- 导航误差(NE):计算无人机最终位置与目标之间的平均距离。
对比基线
随机(Random):无人机随机选择轨迹姿态,不进行结构化规划或指导。该方法用于展示解空间的范围。
固定动作(Fixed Action):无人机将助理指令映射为预定义的固定动作。例如,“巡航”表示向前移动 5 米,“左转”表示转 30 度后向前移动 5 米。
跨模态注意力(Cross-Modal Attention,CMA):CMA 模型常用于视觉语言导航任务,采用双向 LSTM 同时处理图像输入和指令理解。为了适应我们的任务,作者修改了其递归预测器,使其输出一组轨迹,而非传统导航动作。
定量结果
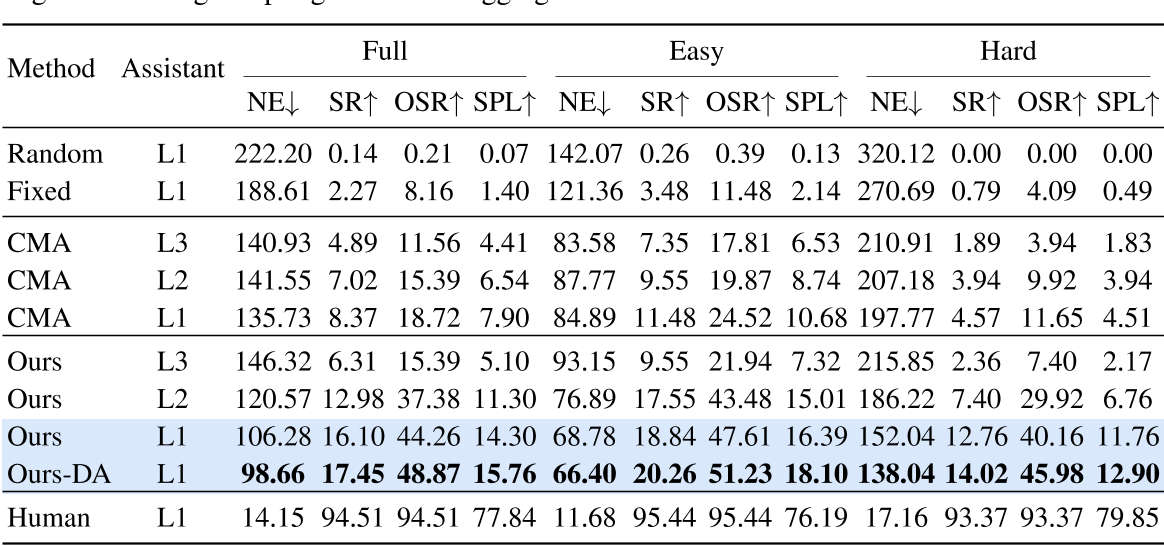
表2:不同助理水平的已见测试集结果,DA 指的是使用基于回溯采样的数据聚合方法训练的模型。
与基线的比较
表 2 显示,在测试的已见环境中,作者的方法在不同难度等级的所有指标上均优于基线。在不同助理级别下,成功率(SR)指标相比 CMA 模型平均提升了 5%。这表明基于多模态大语言模型(MLLM)的层次化轨迹生成方法增强了场景理解能力,能够生成更准确且更具适应性的姿态序列,从而最终提升了决策质量和整体性能。
传统的基线模型 CMA 由于模型规模和任务复杂度的限制,在多个指标上表现不佳。随机(Random)和固定动作(Fixed)方法难以完成任务,证明了在不理解指令和视觉信息的情况下,完成目标搜索任务极为困难。
作者还评估了通过回溯采样数据聚合训练的模型,结果显示相比原始模型成功率有所提升,表明该方法增强了无人机的导航能力。
此外,作者评估了在 L1 级助理指导下由人类操控无人机的表现。如表 2 所示,人类在任务中取得了较高的成功率,但有时会选择更长的路径。这表明虽然人类能够做出正确决策,但他们可能更倾向于谨慎或探索性的路线,从而导致路径规划效率略有下降。
不同助理级别下的比较
在 L1 助理的持续引导下,作者的方法达到了最高的成功率。随着助理级别的提高,无人机代理需要更多依赖自身的导航规划能力来完成任务。结果显示,在助理级别较高时,作者的方法和 CMA 方法的成功率及其他指标均有所下降,表明无人机执行长期视觉语言导航任务具有极大挑战性。
对未见情况的泛化能力
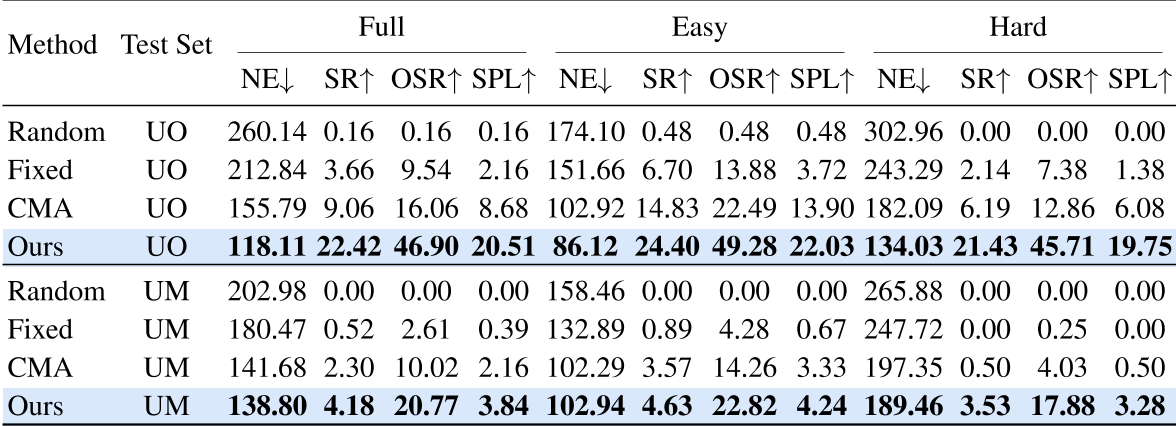
表3:使用L1辅助的不同测试集的泛化能力,其中 UO 和 UM 分别代表未见物体测试集和未见地图测试集
表 3 展示了模型在未见数据集上的表现,突显了作者方法出色的零样本能力及对新场景的适应性。作者的方法在未见物体测试集上的成功率甚至略高于已见测试集,这可能归因于作者方法中使用的 Grounding DINO 模块天生的泛化能力以及数据的相对简单性。在未见场景测试集中,固定动作方法的低成功率反映了环境的复杂性。虽然作者的方法在该测试集中表现有所下降,但依然优于其他方法。
性能可扩展性
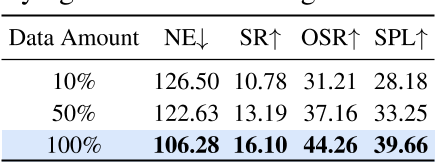
表4:不同训练数据量下的性能可扩展性
表 4 报告了模型在不同训练数据量及 L1 助理条件下的表现。结果表明,随着训练数据量的增加,模型性能得到提升,说明更大规模且多样化的数据集有助于增强模型的理解和决策能力。
定性结果

图4:对象搜索结果的可视化
图 4 展示了在 OpenUAV 平台上评估的两个示例。前两行显示无人机成功遵循指令,穿越建筑群,最终定位到一辆黄色车辆。在此过程中,由于无人机姿态变化,摄像机视角发生了切换,体现了平台的真实感和高保真度。相比之下,第三行展示了无人机在穿越森林区域时因飞行高度不足而发生碰撞的情况,突显了复杂环境带来的挑战。
总结
作者从平台、基准测试和方法论三个方面,解决了真实无人机视觉语言导航(UAV VLN)面临的挑战。为此,作者开发了 OpenUAV 平台,提供真实的环境、飞行仿真和全面的算法支持。还构建了面向目标的真实 UAV VLN 数据集,并提出了 UAV-Need-Help 基准测试,利用助理引导无人机完成复杂的 VLN 任务。
此外,作者提出了一种无人机导航大语言模型(UAV Navigation LLM)及基于回溯采样的数据增强策略,这两者有效提升了基于轨迹的真实 VLN 任务性能。作者的工作建立了一个统一的真实 UAV VLN 研究框架,推动了仿真与现实无人机导航应用之间的融合。
未来在真实 UAV VLN 任务中,有两个有前景的研究方向:
- 增强无人机的自主导航能力,使其在复杂环境中能以最少的指导自主高效运行。
- 提高无人机仿真到现实环境的迁移能力,促进无人机在实际场景中的应用。
