
简谈自动驾驶与各大车企的核心战略
第一部分:什么是自动驾驶?(L0-L5)
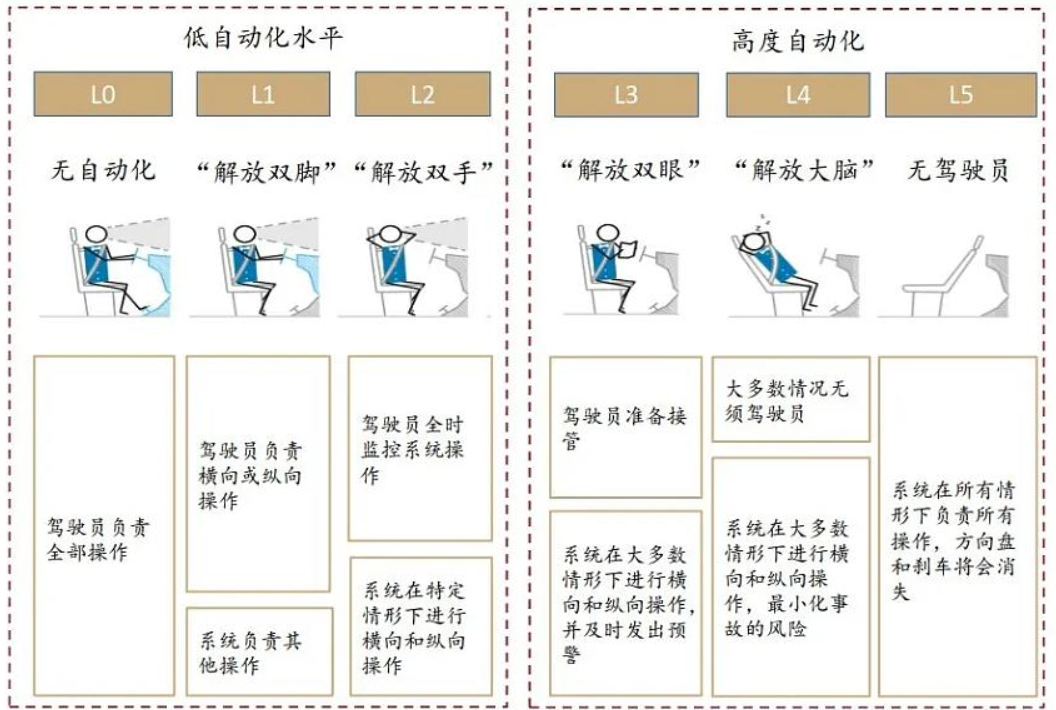
目前,全球广泛采用的是由SAE(国际汽车工程师学会)制定、并被中国汽车技术研究中心有限公司等机构采纳的分级标准 1。该标准将驾驶自动化分为0至5级。
自动驾驶的六个级别(SAE J3016标准)
L0(应急辅助 / 无自动化): 驾驶员执行全部驾驶任务。系统仅提供警告,如前方碰撞预警或车道偏离警告,但系统本身不会介入车辆控制。
L1(驾驶辅助): L1是驾驶员的“帮手”。系统可以辅助执行一项纵向(加减速,如自适应巡航)或横向(转向,如车道保持)的控制,但不能同时执行。
L2(组合驾驶辅助 / 部分自动化): 系统的核心是辅助 。系统可以同时辅助执行纵向和横向的控制,例如同时启用自适应巡航和车道居中。在L2功能启用时,驾驶员必须全程处于驾驶状态,持续监控驾驶环境,并随时准备接管。驾驶员对车辆的安全负有全部责任。
L3(有条件自动驾驶):在满足特定运行条件(如高速公路、特定速度)时,系统可以持续执行全部驾驶任务。在此期间,驾驶员可以不监控驾驶环境。
L2与L3的根本区别不是技术能力问题,而是法律和责任问题。L3代表了“责任的移交”——当L3功能激活时,如果发生事故,责任由OEM(汽车制造商)承担,而不是驾驶员。
这解释了为什么尽管当前市场上的高级辅助驾驶功能(如特斯拉的FSD Beta、小鹏的XNGP、理想的AD Max)在技术表现上已接近L3,但在法律上仍被严格定义为L2系统 。因为它们都要求驾驶员必须时刻监控并准备接管。L3的商业化进展缓慢,正是因为制造商在法律和保险层面需要承担巨大的责任。
- L4(高度自动驾驶): L4系统能在限定的运行设计域(ODD)(例如特定的城市区域、特定的天气条件)内,持续执行全部驾驶任务,且不需要驾驶员接管 。这就像在固定区域内打无人驾驶出租车。
- L5(完全自动驾驶): 这是自动驾驶的终极形态。系统能在任何条件下执行所有驾驶任务,完全不需要人类干预,车辆甚至可以不设计方向盘和踏板。
第二部分:核心路线:视觉 vs. 融合
在自动驾驶的实现路径上,行业长期存在两条截然不同的技术哲学——即车辆应该如何感知世界。
2.1 特斯拉的“纯视觉”路线
特斯拉的路线以其马斯克的著名论断为代表,他称激光雷达(LiDAR)是“傻瓜的差事”。
- 核心论据(人类类比): 人类仅凭两只眼睛(视觉)就能完成复杂的驾驶任务。因此,一个配备多个摄像头的先进AI系统,也应该能做到。
- 核心论据(根本问题): 激光雷达回避了自动驾驶的根本问题——“视觉识别”。系统必须理解它看到的是一个(可穿过的)塑料袋还是一个(危险的)橡胶轮胎,而激光雷达只能“看到”一个障碍物。
- 商业考量: 摄像头成本低廉、易于规模化部署。而早期的激光雷达不仅价格昂贵,且在外形上难以集成 。
- 技术缺点: 纯视觉方案在“边缘案例”(edge cases)中表现不佳。例如,它难以应对恶劣天气(雨、雪、雾) ,或者在面对强烈的日落眩光时,摄像头会短暂“失明” 。
2.2 “传感器融合”路线
“传感器融合”是行业内更主流的路线,其核心思想是通过多模态传感器的冗余来构建一个更鲁棒的感知系统。
- 核心论据(互补优势): 不同的传感器是互补的,而非竞争关系。
- 摄像头(Cameras): 成本低,分辨率高,善于“识别”和“分类”(如看懂交通标志、红绿灯)。
- 激光雷达(LiDAR): 通过发射激光脉冲,能生成极其精确的三维点云,准确测量距离和位置,不受光照影响。
- 毫米波雷达(Radar): 善于直接测量物体的“速度”(多普勒效应),且穿透性强,在雨、雾等恶劣天气中表现优异。
- 技术缺点: 融合方案的系统复杂度极高。
- 成本高: 高性能LiDAR和雷达会增加车辆成本。
- 数据冲突: 传感器之间可能产生“分歧”(disagreement),例如摄像头认为无障碍,雷达却检测到物体,系统需要复杂的算法来仲裁。
- 工程复杂: 多传感器的校准、维护、数据同步和模型训练都极其复杂。
2.3 辩论的演变——从“硬件”到“AI架构”
在2024至2025年,“纯视觉 vs. 融合”的辩论正在发生根本性的转变。这场辩论正从“传感器硬件之争”转向“AI软件架构之争”。
行业发现,仅仅堆叠LiDAR等硬件并不足以解决问题;如果AI模型无法有效“融合”这些异构数据,系统性能依然低下。
讽刺的是,作为全球首家在量产车上搭载LiDAR的中国车企小鹏,其高管在2025年慕尼黑IAA车展上却发表了惊人言论。据报道,小鹏自动驾驶中心负责人表示,“LiDAR数据无法对(新的)AI系统做出贡献” 。
这并非是说LiDAR本身无用,而是揭示了一个更深层的趋势:小鹏(包括理想)正在转向的VLA(Vision-Language-Action,视觉-语言-行动)或“端到端”大模型,其训练数据主要是海量的“视频片段”(Vision)。与其花费巨大的算力去融合异构的LiDAR点云,不如将所有算力集中用于训练一个更强大的、以视觉为中心的AI模型。
结论是,特斯拉的“纯视觉”(即依赖海量视觉数据来训练大模型)似乎正在被行业验证,即使是那些曾经的“LiDAR拥护者”,也在AI架构上向其靠拢。
第三部分:头部品牌的具体路线分析
基于上述基础,我们可以清晰地解构研讨会关注的几家头部品牌,它们已经走出了截然不同的差异化路线。
3.1 特斯拉:教条的“纯视觉”与“端到端”终局
- 技术路线: 坚定执行“纯视觉” ,并率先在行业内推动“端到端”神经网络。
- 架构解释:
- 旧模式(模块化): 感知、预测、规划是三个独立的模块,由不同团队编写规则。
- 新模式(端到端): 整个系统是一个巨大的神经网络(“黑匣子”),输入是摄像头原始视频,输出是方向盘和踏板的控制指令。这更像人类的“直觉”驾驶,减少了中间环节的规则干预。
- 终极目标: FSD(Full Self-Driving)的真正目的不是辅助驾驶,而是为L4/L5级别的“无人驾驶出租车”(Robotaxi)网络积累数据和迭代算法。
- 重点关注:无方向盘汽车(CyberCab)
- 特点: 该车型没有设置方向盘和踏板,并引入了无线感应充电技术 。
- 时间: 发布会明确指出,CyberCab预计在2026年投入生产。
- 成本: 其目标整车成本将低于3万美元。
3.2 华为:智能汽车界的“技术赋能者”
战略定位:华为坚持“不造车”,而是作为“智能汽车时代的博世(Bosch)”,向车企(如赛力斯、奇瑞、江淮、北汽、广汽等)提供全栈智能解决方案。
技术路线: “乾崑(Qiankun)”智能驾驶解决方案。
核心架构(ADS 4): 采用“WEWA”(World Engine + World Behavior Model,世界引擎+世界行为模型)架构 。
独特优势: 华为的独特优势在于其强大的“云端”能力。他们利用AI在云端生成海量的、真实世界中罕见的极端(Corner Cases)驾驶场景,再用这些数据来训练车端的AI模型,即“用AI训练AI”,以此解决行业普遍面临的“难例数据”瓶颈。
要尽量避免遇到自动驾驶的"难例数据",其实在某种程度上比拼的就是数据。但是数据数据采集是有成本的,如何高效低成本的采集corner case 数据,是自动驾驶感知开发需要思考的一个问题。
3.3 理想:VLA路线
- 技术路线: “VLA(视觉-语言-行动)”路线。
- 战略叙事: 理想汽车的战略高明之处在于其强大的“叙事能力”。他们将其自动驾驶的发展清晰地划分为三个“进化”阶段,帮助用户理解其技术迭代:
- 第一阶段(昆虫智能): 2021年起,依赖“规则算法 + 高精地图”。
- 第二阶段(哺乳动物智能): 2023年起,采用“端到端 + VLM(视觉语言模型)”。
- 第三阶段(人类智能): 2024年起,即VLA模型。
- VLA的本质: 理想的VLA模型,不仅要“看”(Vision)和“行动”(Action),更要“理解”和“推理”(Language, CoT - 思维链) 。它旨在解决“端到端”模型的“黑匣子”问题。虽然理想的路线偏向端到端,但是它在端到端架构中引入语言理解与语义可解释层,让模型能“说出自己在想什么”,从而部分解决黑匣子问题。
3.4 小鹏:L3冲刺
- 战略定位: “AI技术激进派”。
- 技术路线: XNGP(Navigation Guided Pilot)系统,由“图灵AI智驾系统”(Turing AI)驱动。
- 核心驱动: 1. 依托一个720亿参数的世界基座模型。 2. 采用“端到端”大模型,目标是实现从“车位到车位”的全场景(城市、高速、园区、停车场)覆盖。
- 激进的时间表: 小鹏是目前行业中对L3承诺最激进的。其计划在2025年底,在中国内地实现全场景L3级自动驾驶。
- 战略意义: 结合第一部分的分析,这意味着小鹏最有可能成为首批准备在法律上为自动驾驶“负责”的主机厂,这将是行业的一个重大里程碑。
3.5 蔚来:“基础设施协同”的独特路线
- 技术路线: 坚持全栈自研(NAD),并在“传感器融合”路线上走得最彻底。
- 硬件堆栈: “蔚来超感系统”(NIO Super Sensing)是当前量产车的硬件“天花板”。该系统配备多达31个高性能感知硬件,包括3个激光雷达(1个超远距、2个侧面广角)、4D成像雷达和800万像素摄像头等。这与特斯拉的纯视觉路线形成了鲜明对比。
- 杀手级应用: 蔚来的NAD(NIO Autonomous Driving)可以实现“高速服务区领航换电” 。车辆可以自主导航驶入服务区,自动排队并全自动完成换电,然后再自主导航返回高速。这是目前唯一一个将L4级自动驾驶应用与能源补给网络(换电站)深度绑定的商业模式,创造了竞争对手无法复制的独特用户体验。
总结:各大车企的路线对比
| 车企 | 路线归类 | 关键架构/说明 |
|---|---|---|
| 特斯拉 | 端到端 (End-to-End) | 最坚定的“纯视觉+端到端”路线执行者。其FSD V12被认为是行业内首个大规模应用的“端到端”模型,输入为摄像头视频,输出为驾驶指令。 |
| 小鹏 | 端到端 (End-to-End) | 非常明确的“端到端大模型”战略。其“图灵AI智驾系统” 和VLA(视觉-语言-行动)模型均基于此架构,旨在实现“车位到车位”的全场景覆盖。 |
| 理想 | 从"模块化"转向"端到端" | 理想清晰地展示了其进化路径:第一阶段(2021年起)依赖“规则算法”(模块化);第二阶段(2023年起)转向“端到端+VLM”;第三阶段(2024年起)进化为VLA(视觉-语言-行动)大模型。 |
| **华为 ** | 大模型驱动 (类端到端) | 华为的“乾崑”ADS 4采用了WEWA(世界引擎+世界行为模型)架构,被称为“业内首个智驾原生基模型” 。这是一种基于AI大模型的先进架构,本质上是“端到端”的实现路径。 |
| 蔚来 | 大模型驱动 | 蔚来的技术架构基于“AI大模型”,通过全栈自研,整合感知与决策,实现智能驾驶。虽然没有像小鹏那样高调宣传“端到端”,但其技术基础已是AI大模型,而非传统的“规则”模块。 |
总结: 目前,行业头部玩家(包括特斯拉、小鹏、理想、华为)已经达成了共识,即“端到端”的AI大模型是自动驾驶的未来。传统“模块化”路线正在被淘汰,各家公司正处于从“模块化”向“端到端”过渡的不同阶段。
核心原因:
传统“模块化”路线依赖人类编写的“if-then”规则来分步处理任务(感知、规划、控制)。但现实世界的突发状况无穷无尽,规则永远写不完,且错误会逐级放大。
而“端到端”大模型则不再依赖规则,而是像人一样,通过观看海量的驾驶数据来“自学”驾驶。它将“输入”(传感器)直接映射到“输出”(驾驶指令),擅长“举一反三”,因此被认为是唯一能解决复杂状况、实现真正自动驾驶的路径。
