
transformer
最早的transformer = encoder + decoder
CNN与NLP的形象类比关系
CNN:
针对一个图片,可以理解为一张二维的像素图,有多个通道。
NLP:
针对一句话,拆分为n个token,每个 token 经过 embedding 后,表示为一个固定维度的向量。
每个token可以理解为CNN中的一个像素点(贯穿多个通道,通道数即 embedding 维度)。
所有的token合起来就是一个像素图(贯穿多个通道)。
Layer Normalization
Batch Normalization (BN) 虽然在 CNN 上效果很好,但在以下场景存在致命缺陷,促使了 LN 的诞生:
- RNN/LSTM 等序列模型:序列长度不固定。如果在不同时间步做 BN,统计量会波动极大且难以维护。
- 小 Batch Size (甚至 Batch=1):大模型(如 LLM)训练时显存受限,Batch Size 往往很小,此时 BN 的统计量估算失效。
LN 通过抛弃对 Batch 维度的依赖,完美解决了上述问题。
1. LN 和 BN 的区别
很像,但是:
假设输入张量形状为
BN (纵向切):固定 Channel,跨越 Batch () 统计。
在cnn中,可以想象成把一个通道的那张图norm。BN 非常适合 CNN。
LN (横向切):固定 Sample (),跨越 Feature () 统计。
在cnn中,可以想象成定一个点,然后垂直和每一个通道的该位置点,合起来一起norm。但是 LN 在 CNN 上表现一般:在图像分类等任务中,LN 往往打不过 BN。
- 原因:图像的特征(Channel)之间差异很大(比如边缘检测 vs 颜色检测),强制把它们拉到一个分布可能会破坏图像的空间/语义信息。
2. 对于Transformer,用LN
原因:
- 序列长度不定:NLP 句子有长有短,BN 需要对齐长度(Padding),Padding 的 0 值会严重干扰 BN 的均值方差计算。
- 样本统计不稳:NLP 数据的 Batch 统计量往往不如图像稳定,且 Batch Size 受显存限制通常较小,BN 效果差。
encoder
Bert结构
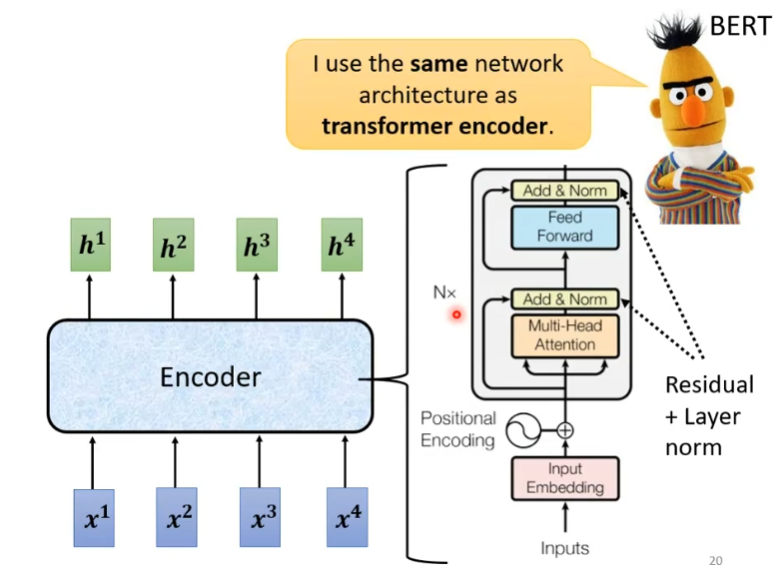
上图其实就是Bert的结构,Bert本质上就是一个编码器。
输入是四个向量,输出是四个处理后的特征向量(包含了上下文信息,且与x一一对应)。
首先对输入的向量,进行位置编码,然后送入一个多头的Attention,让模型在处理当前单词时,能够“关注”到句子里的其他单词。
然后Add: 指的是 Residual Connection (残差连接)。看旁边的箭头,输入直接绕过了 Attention 层加到了输出上。这能防止网络过深导致的退化。同时Norm: 指的就是 Layer Normalization (LN)。
接着进入一个就是一个简单的全连接网络(MLP),对特征进行进一步的非线性变换。
最后再次Add和Norm,输出。
BERT 就是一堆 Transformer Encoder 叠起来。每个 Encoder 层里有两步核心操作:先做注意力 (Attention),再做前馈 (Feed Forward),每一步做完都要记得 Add & Norm (残差+层归一化)。
在 BERT/Transformer 的图里,“前馈”就是一个负责特征提取和非线性变换的“加工厂”。它没有记忆功能(不存状态),只是单纯地把上一层给它的数据处理好,然后扔给下一层。
Decoder
Decoder的结构
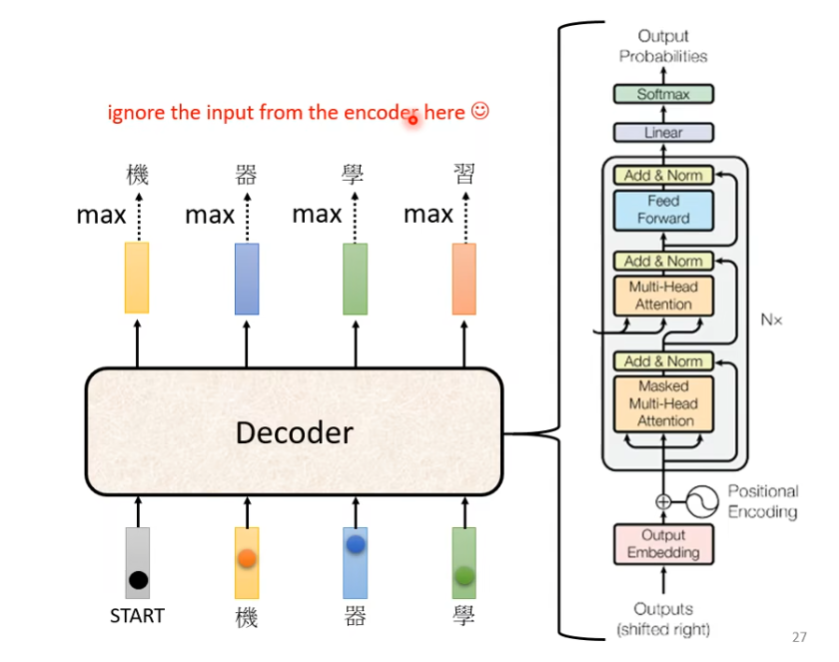
Transformer 的 Decoder 是一种用于序列生成的网络结构,
它通过“因果自注意力(Causal Self-Attention)”实现 autoregressive(自回归)建模。
Masked Self-attention
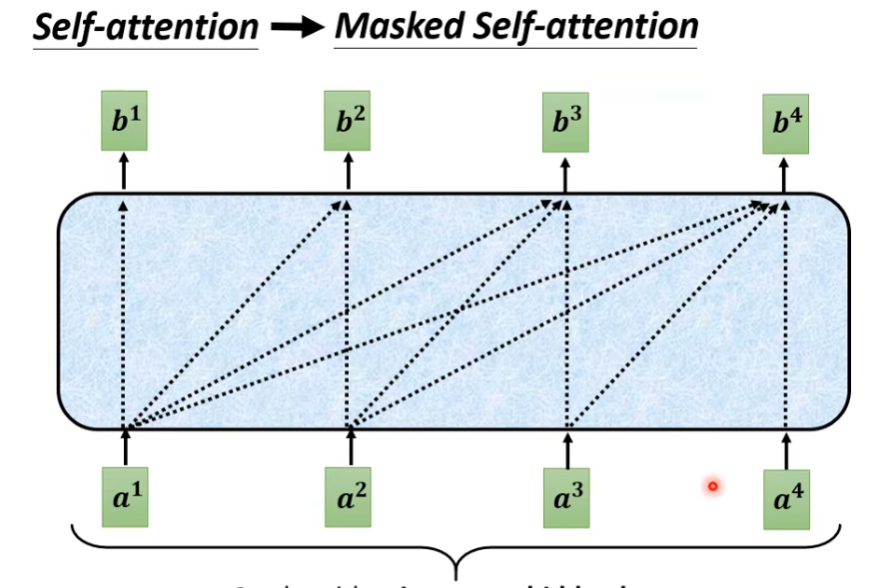
和Self-attention的区别是,的生成之和到有关,不考虑后面的。
为什么要masked?
因为Decoder的输入不是一下子把所有的都给出来,而且先,再一个一个到。
Encoder和Decoder的连接
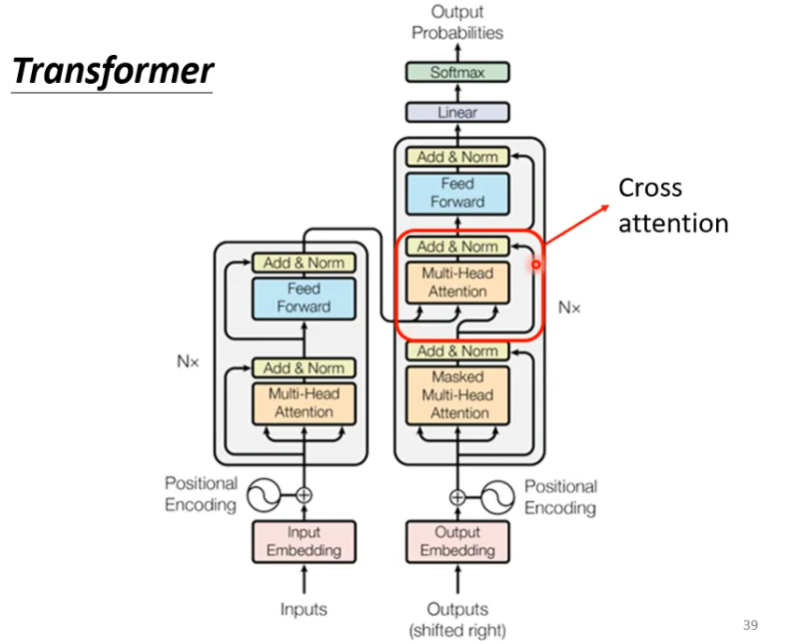
Cross attention
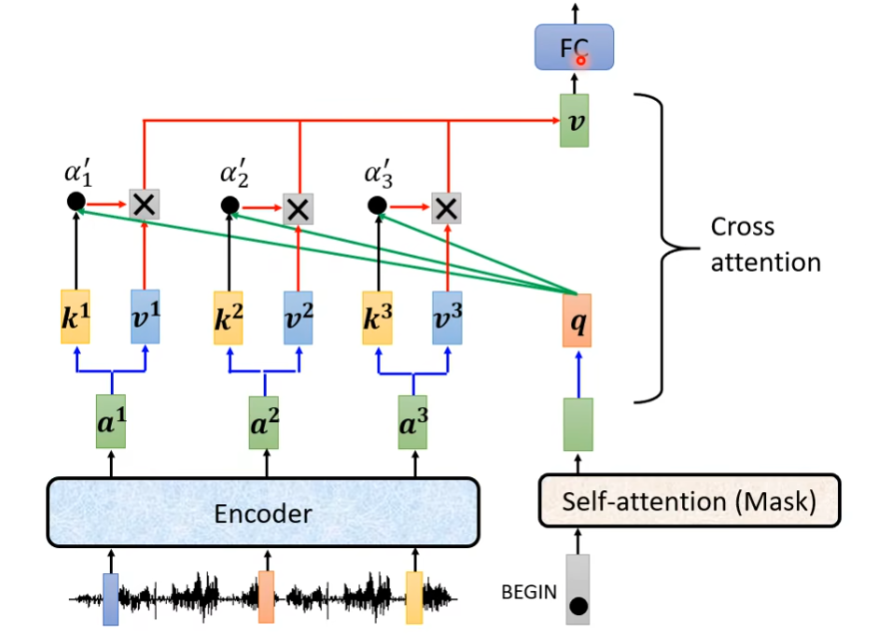
Cross-Attention 是Decoder 在生成当前 token 时,去“查询(Query)Encoder 输出”的机制。
Decoder产生Q去查询Encoder的K和。
seq2seq模型的训练
Seq2Seq(Encoder–Decoder)模型的训练方式是: 用“已知的目标序列”作为 Decoder 的输入, 通过 autoregressive 预测下一个 token, 对每一步计算交叉熵损失,并整体反向传播。
这套方法有个名字:Teacher Forcing。
为什么什么用“已知的目标序列”作为训练Decoder的输入呢?
Decoder 训练时输入目标序列,不是让模型“抄答案”,而是让它在“正确历史条件下学习如何预测下一个 token”,这使得序列生成可以并行训练。
暴露偏差(Exposure Bias)
模型训练时只“暴露”在真实历史上, 推理时却必须在“自己生成的历史”上继续预测。明知道有暴露偏差,为什么还要 Teacher Forcing?
1. 不 teacher forcing,根本训不动
- 初期模型输出几乎是随机
- 输入错误上下文 → 梯度噪声巨大
- 训练不稳定,甚至发散
2. Transformer 需要并行训练
- 自回归采样:必须一步步生成
- Teacher forcing:一次 forward 算所有位置
3. 实际效果好
- 大模型 + 大数据
- 暴露偏差在实践中被“规模”压住了
