
DL_Note
如何优化代码
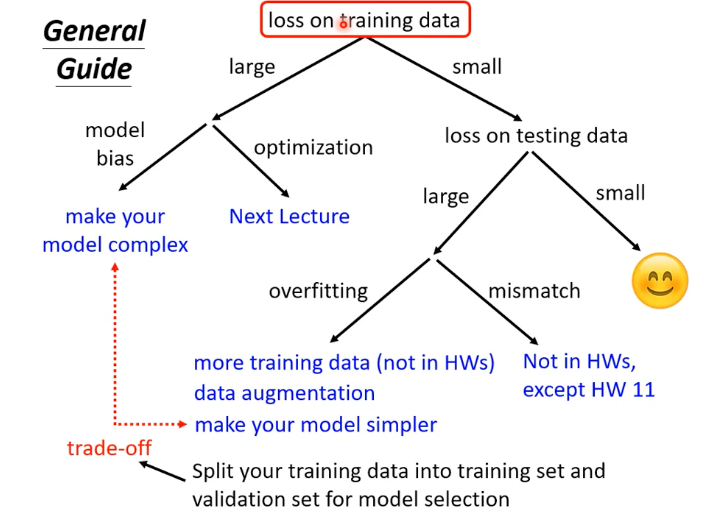
1. 诊断步骤:检查训练数据上的损失 ()
首先检查模型在训练集上的表现。
| Ltrain | 问题方向 | 诊断结果 | 解决方案 |
|---|---|---|---|
| 很大 (large) | 1. 模型偏差 (model bias) / 欠拟合 (Underfitting) | 模型过于简单,表达能力不足。 | 使模型更复杂 |
| 很大 (large) | 2. 优化问题 (optimization)(比如说是梯度下降不管用) | 模型理论上能拟合,但优化器未能找到好的权重。 | 调整优化器参数 |
| 很小 (small) | → 进入下一步:检查测试损失。 | 模型已学会训练集数据。 | - |
2. 诊断步骤:检查测试数据上的损失 ()
如果 很小,接着检查模型在测试集上的泛化能力。
| Ltest | 问题诊断 | 解决方案 |
|---|---|---|
| 很大 (large) | 1. 过拟合 (overfitting) | 模型过度学习训练集细节和噪声。 |
| 很大 (large) | 2. 错配 (mismatch) | 训练集和测试集的数据分布不一致。 |
| 很小 (small) | 模型表现良好 😊 | - |
总结
欠拟合 (高偏差) 的解决方案是使模型复杂。
过拟合 (高方差) 的解决方案是使模型简单。
在两者之间寻找平衡是深度学习调参的关键。
模型的弹性:
一个有弹性的模型不会因为一点点噪声就崩溃或做出荒谬的预测,它能持续稳定地在各种复杂和变化的环境中提供有用的结果。
如何处理过拟合
1.数据层面
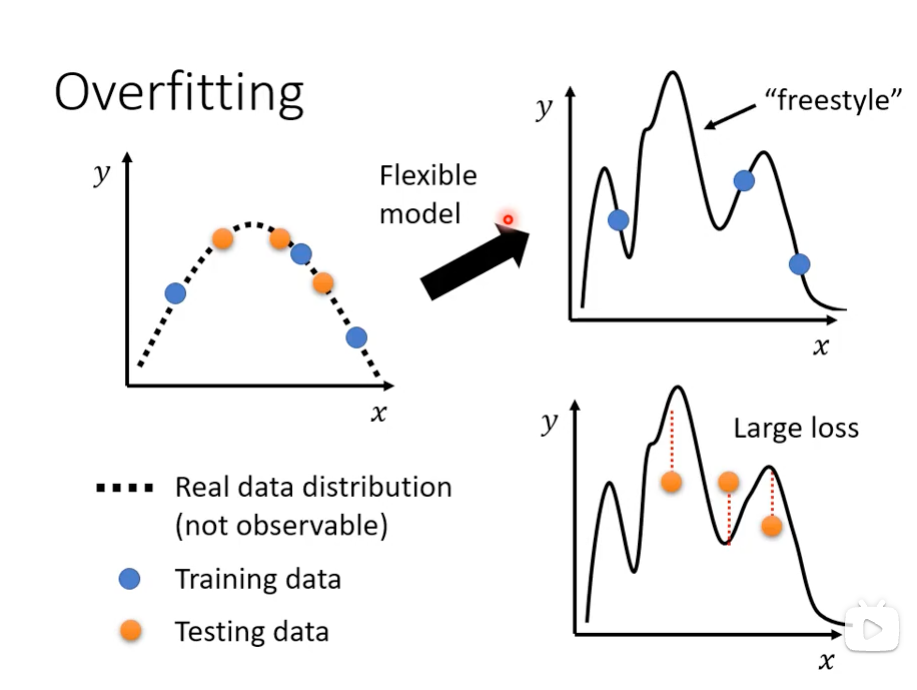
增加训练数据 (More Training Data): 这是最可靠的方法,直接提供更多、更具普遍性的样本,迫使模型学习更抽象的特征。
数据增强 (Data Augmentation): 通过对现有数据进行系统性变换(如图像的旋转、裁剪、色彩变换等),人工扩展训练集的规模和多样性。
2.模型层面
K折交叉验证
K 折交叉验证的基本步骤如下:
1. 划分数据集
将整个可用的数据集(通常是训练集和验证集的总和,不包括测试集)随机地分成 个大小相等的子集(或称“折”/“Fold”)。
2. 进行 K 次循环训练
进行 次独立的模型训练和评估循环:
- 验证集 (Validation Set): 在第 次循环中,将第 个子集作为验证集。
- 训练集 (Training Set): 将剩下的 个子集合并起来作为训练集,用于训练模型。
3. 性能平均
每次循环都会得到一个性能指标(例如准确率、损失值等)。最终,模型在交叉验证下的性能就是这 次结果的平均值。
4.优势
更可靠的性能评估: 由于每个数据点都恰好被用于验证一次,并且被用于训练 次,因此它可以更充分地利用数据,减少了由于随机划分导致的评估偏差。
减少过拟合风险的估计: 它可以更好地估计模型在面对新数据时的泛化能力。
数据利用率高: 在数据集规模较小时尤其有用,它能确保所有数据点都被用于验证。
模型优化失败原因
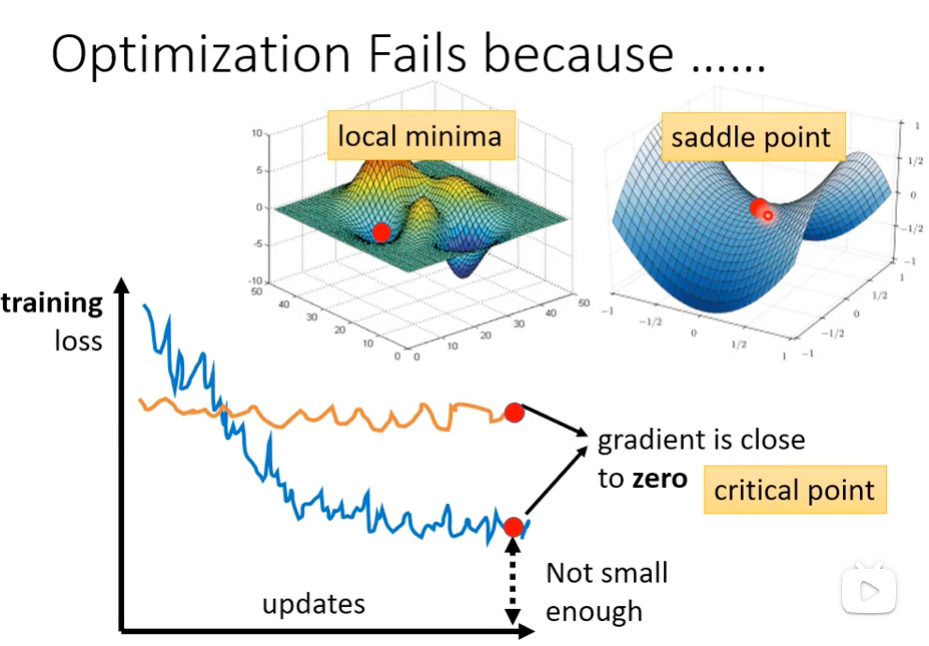
当梯度 () 接近或等于零时,优化器会遇到以下两种主要类型的临界点(critical point):
- 局部最小值 (local minima):
- 描述: 损失曲面中的一个凹陷点,该点的损失值大于全局最小值。
- 影响: 算法到达此点后,梯度为零,参数停止更新,模型被困在一个次优解。
- 鞍点 (saddle point):
- 描述: 损失曲面中的一个点,其梯度也为零,但在某些维度上是向下凸的,而在其他维度上是向上凹的(形状像马鞍)。
- 影响: 在高维空间中鞍点非常常见。算法可能会被困在此点,或者如果使用小批量 SGD 等带有随机性的方法,可能会缓慢地逃离。
如何分辨

泰勒级数近似的核心思想是:在某个点a附近,可以用一个多项式来逼近一个复杂的函数。
比如:$$f(x) = f(a) + f'(a)(x-a) + \frac{f''(a)}{2!}(x-a)^2 $$,x是a附近的点。
当梯度为0,$$ f'(a)(x-a)$$为0,就可以去看$$f(x) = f(a) + \frac{f''(a)}{2!}(x-a)^2 $$,如上图。
Batch和Momentum
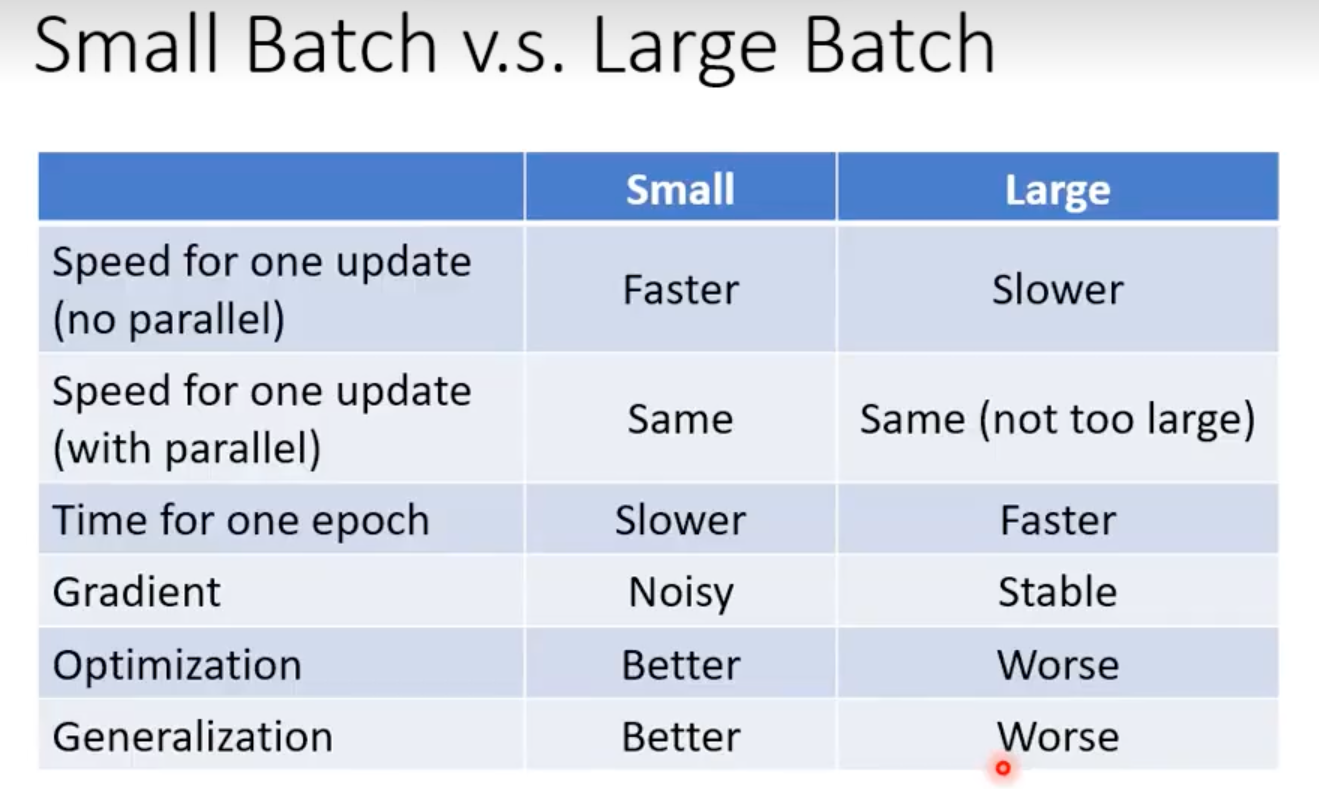
1. Small Batch和Large Batch
Batch 大 → 梯度更稳定 smoother,收敛稳定(不乱跳)
Batch 小 → 梯度噪声大,训练不稳定,但更容易跳出局部最优
超大 batch 会让梯度太准确、太稳定,失去了随机扰动。模型容易陷入 sharp minima、泛化能力变差,而且更新频率更低,学习率调整困难,因此优化效果反而不好。
小 batch 会引入梯度噪声,这种噪声是一种“隐式正则化”,帮助模型找到对测试集更友好的平坦解(flat minima),因此泛化更好。
2. Momentum
Momentum = 梯度下降 + “惯性”
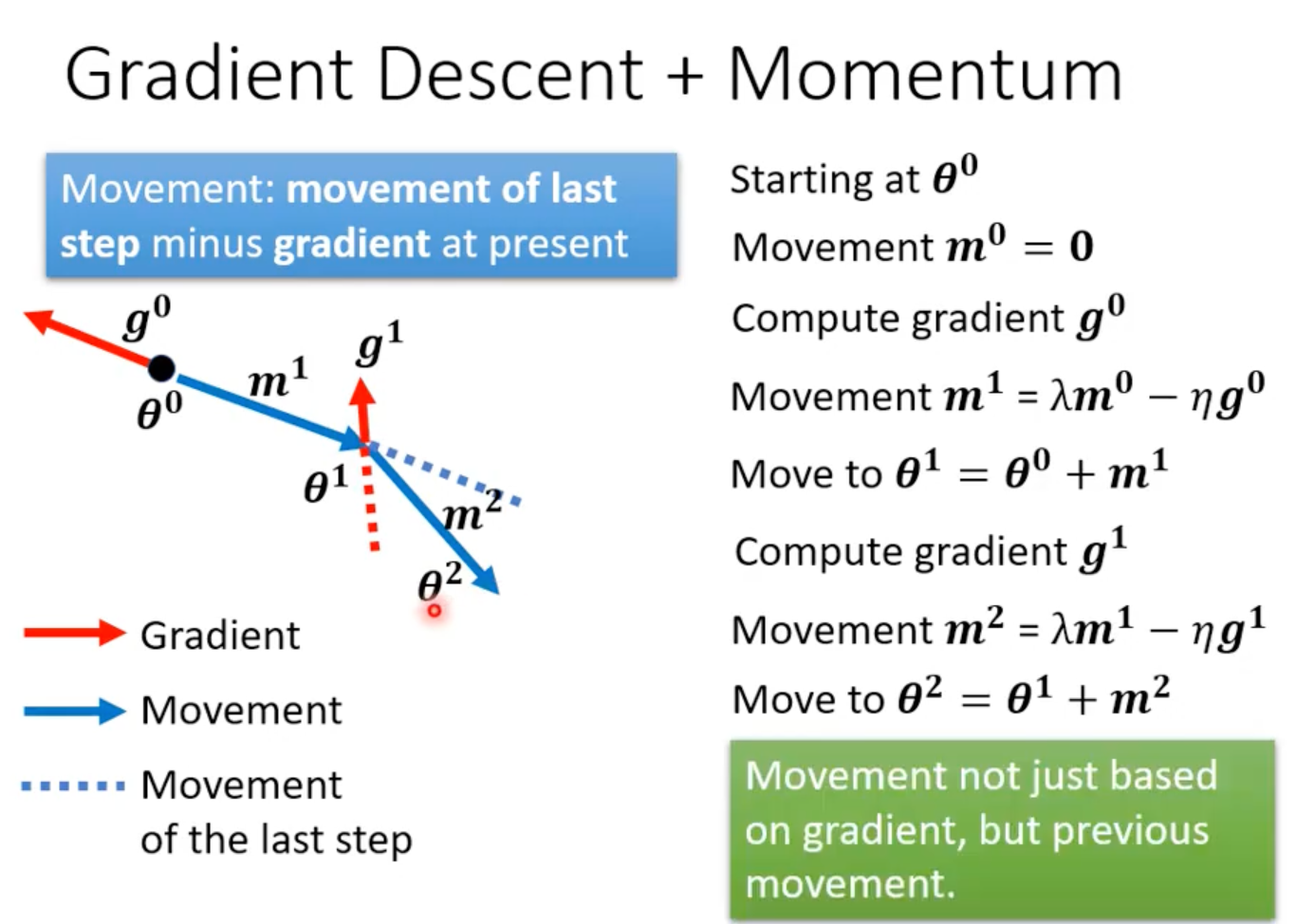
把过去的方向也考虑进去,让更新更有惯性、更平滑。
客制化的LR
一开始大胆试、后期谨慎走
学习率大 → 学得快,但不稳定
学习率小 → 稳定但慢
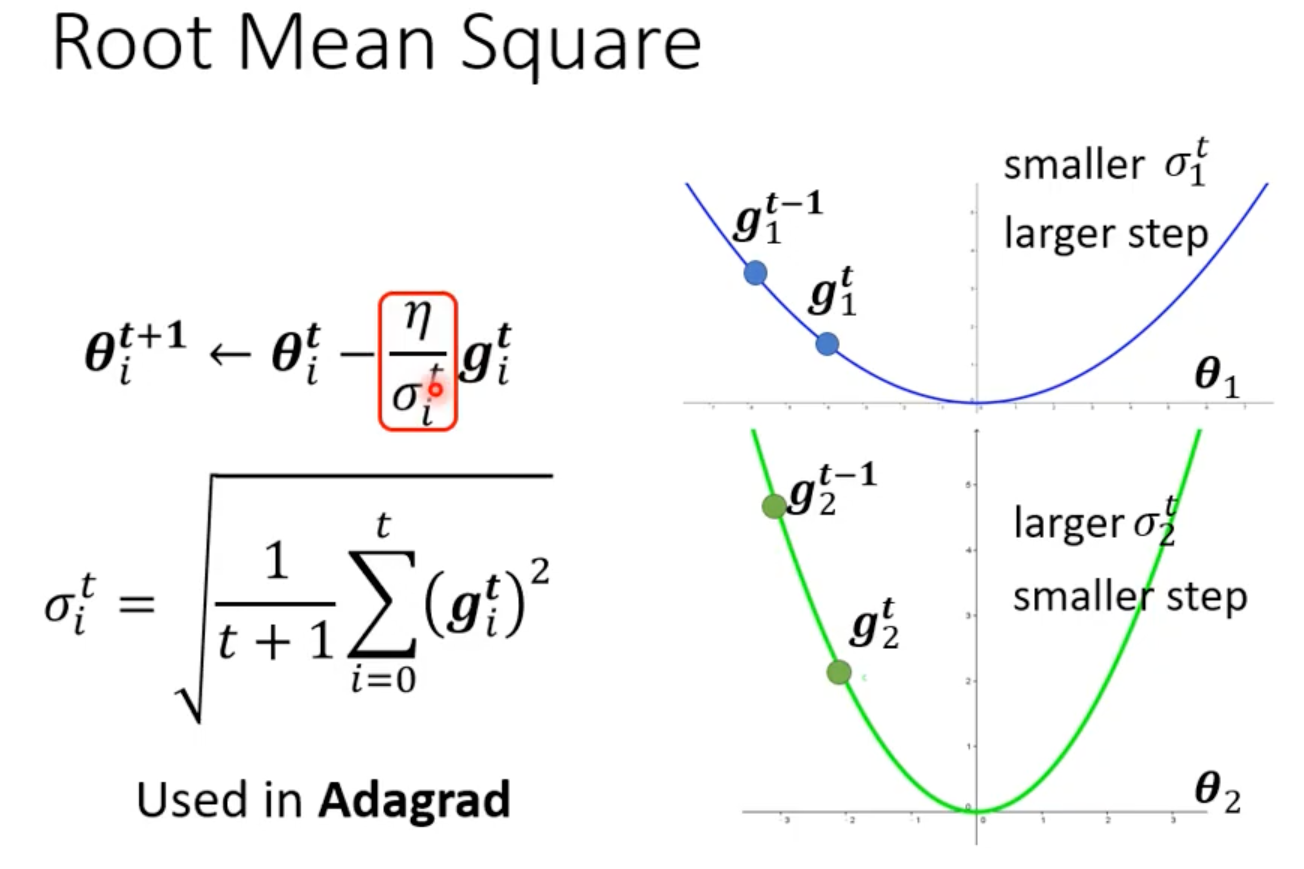
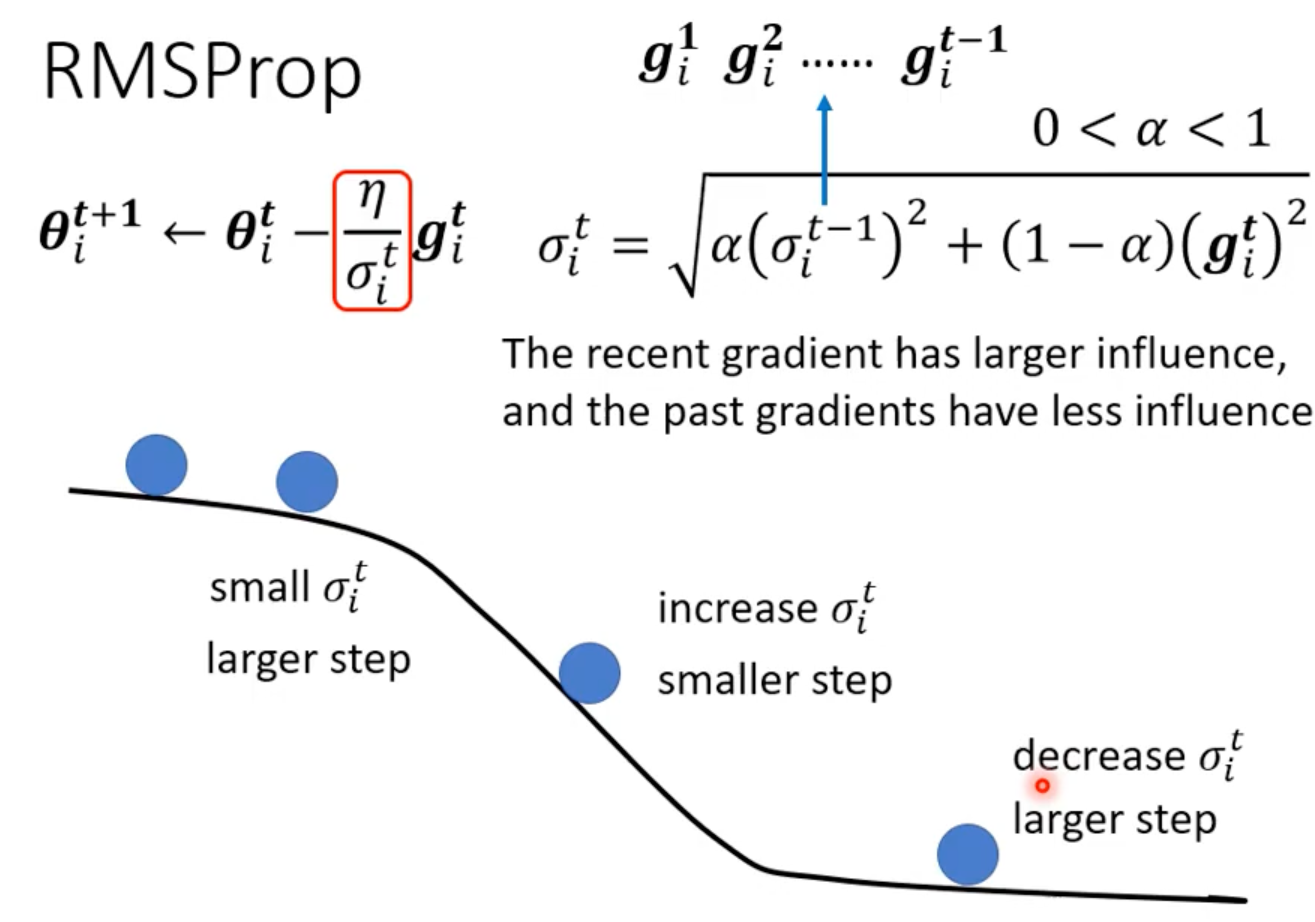
1. 自动调节学习率(Root Mean Square)
RMSProp
:当前梯度
:最近一段时间梯度能量的“RMS 值”
:衰减系数,一般 0.9
Adam = Momentum + RMSProp
2. 学习率调度(Learning Rate Scheduling)
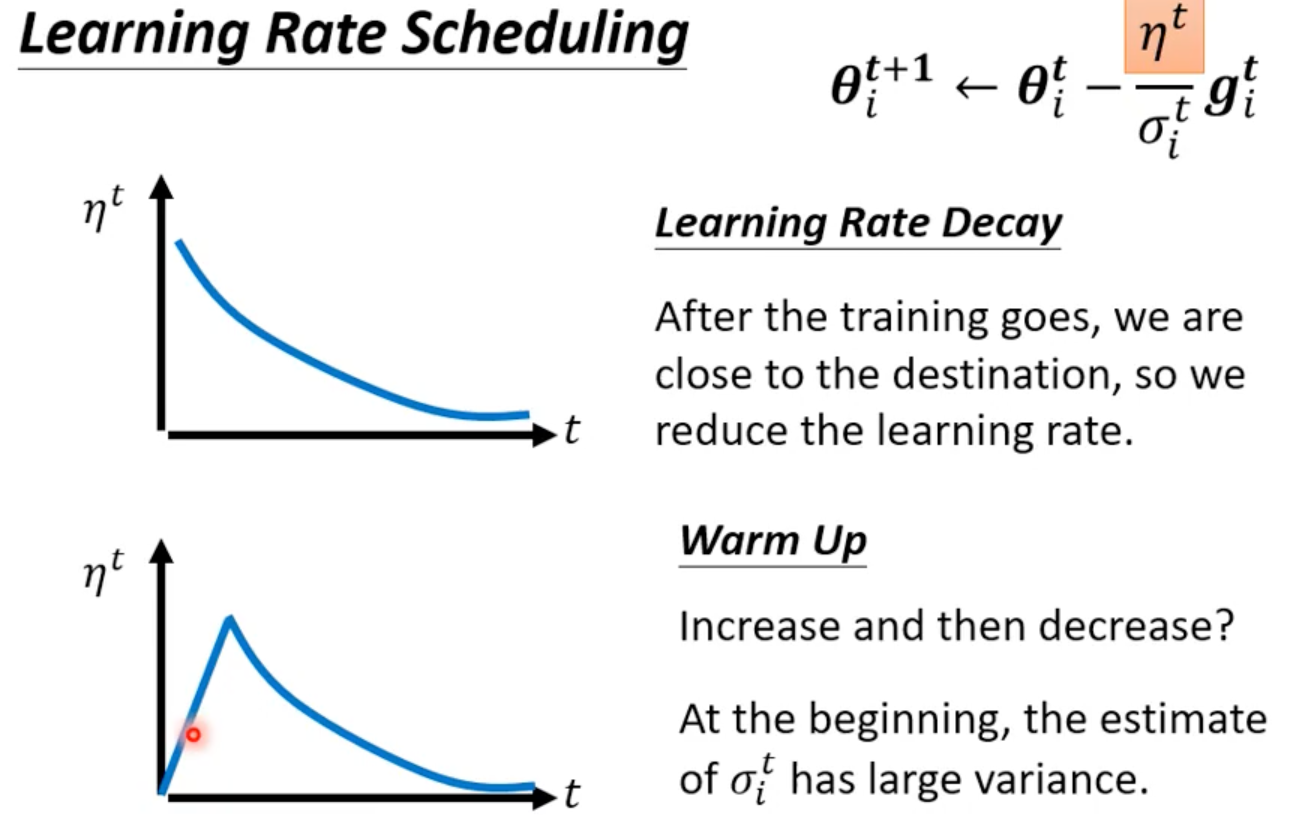
Learning Rate Decay
每隔固定 epoch,把 LR 降低。
✔ 非常平滑
Warm up
训练一开始不要突然用大 LR,先慢慢升上去。
✔ Transformer、中大型模型标配 ✔ 防止训练初期 loss 爆炸

分类(Classification)
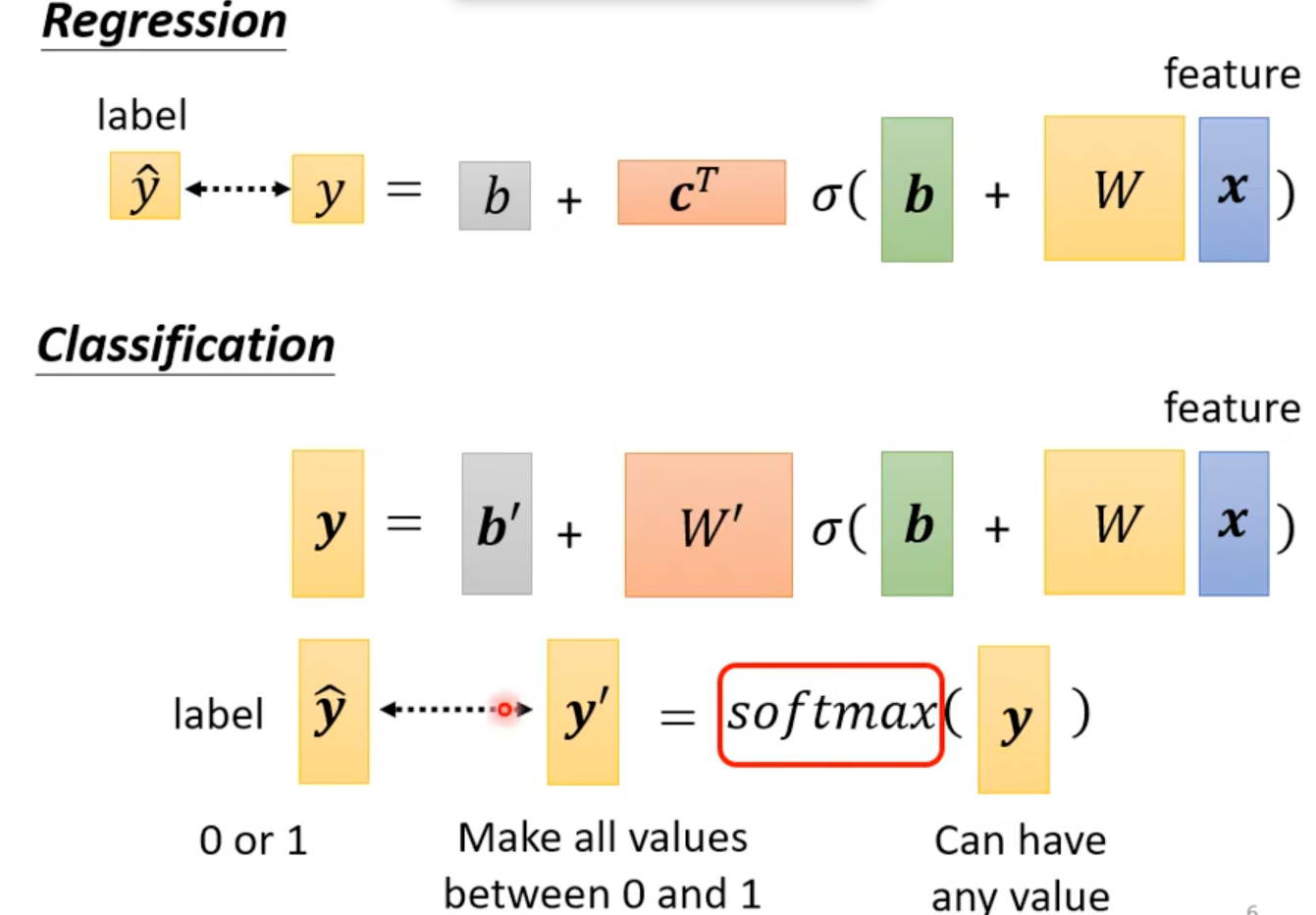
1. Softmax
softmax是深度学习里 把一组数变成“概率分布” 的函数。
它能把任意实数向量转换成:
- 所有值都在 0 到 1 之间
- 所有值加起来 = 1
- 越大的值变成越大的概率
2. 分类问题的Loss
MSE(均方误差)
当 sigmoid 输出接近 0 或 1 时,MSE 的梯度极小,在分类任务中非常差!
回归用 MSE,因为它直接衡量数值差距。
Cross-Entropy(交叉熵)
分类用 CE,因为它对概率敏感、梯度稳定、训练快;
