
Bert
监督学习和自监督学习:
监督学习(Supervised Learning): 使用人工标注的标签进行训练。
自监督学习(Self-Supervised Learning): 不依赖人工标注,通过数据本身构造监督信号。
1. Masking Input
通过随机遮盖部分输入 token,让模型在双向上下文条件下预测被遮盖的词。
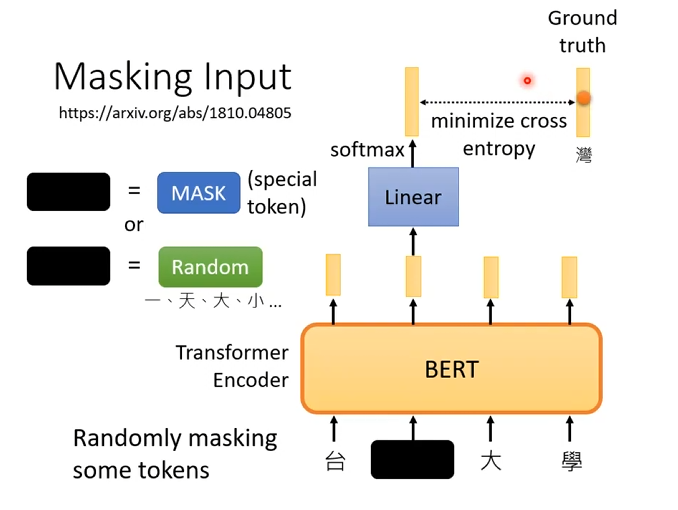
Mask 策略(BERT 原始设定)
对被选中的 token(约 15%):
- 80% → 替换为
[MASK] - 10% → 替换为随机 token
- 10% → 保持原 token 不变
目的: 缓解训练阶段与推理阶段分布不一致问题
训练目标
- 对被 Mask 的位置计算交叉熵损失
- 非 Mask 位置不计入 loss
2. Next Sentence Prediction
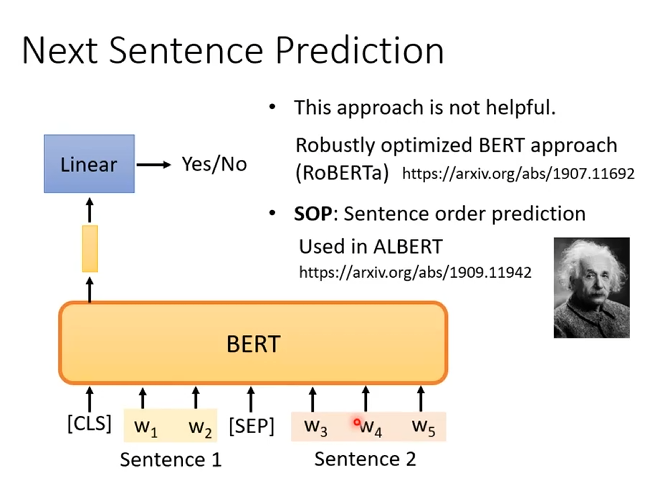
训练目标
- 使用
[CLS]token 的输出表示 - 进行二分类预测:
| 标签 | 含义 |
|---|---|
| IsNext | B 是 A 的下一句 |
| NotNext | B 不是 A 的下一句 |
从语料中构造句子对
(Sentence A, Sentence B):
- 50%:B 是 A 的下一句(IsNext)
- 50%:B 是随机抽取的句子(NotNext)
3. Fine-tune
将bert用于下游任务,此时不再是自监督学习,而是需要人工标注的监督学习。例如下面这几个问题:
序列分类
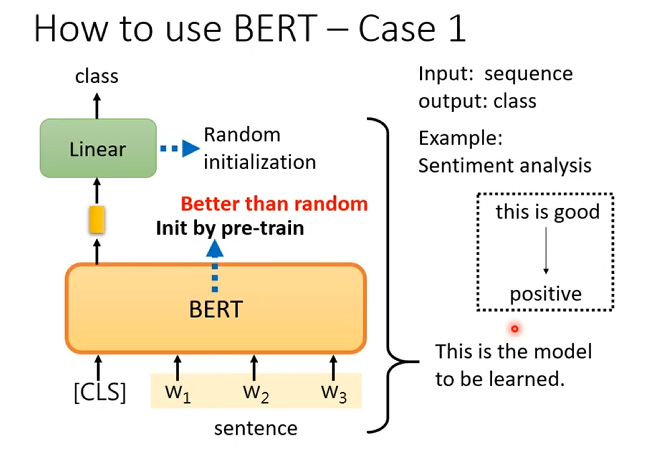
BERT 当编码器用 输入一句话(在最前面加
[CLS]),BERT 输出每个 token 的表示。用
[CLS]表示整句话 取最后一层的[CLS]向量,作为整句的语义表示。接一个简单分类头并微调 在
[CLS]上接一个 线性层(随机初始化) 输出类别; 训练时 分类头 + BERT 参数一起更新。 预训练权重是“比随机初始化好得多的预训练起点”
词性标注
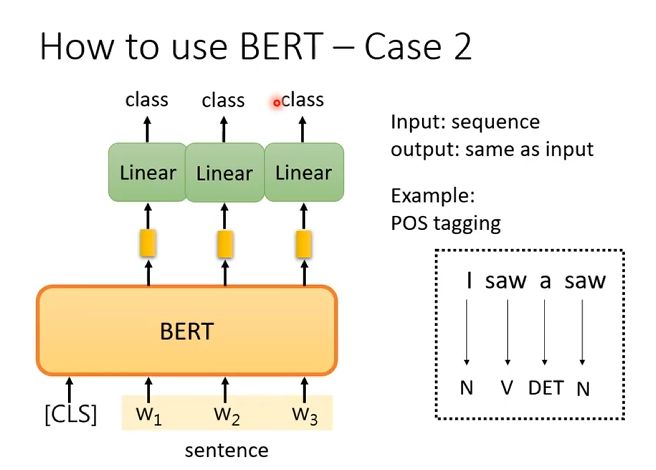
每个 token 都要预测一个标签 输入是一个序列,输出长度和输入一样。
不用
[CLS]做预测[CLS]只作为辅助上下文; 真正用于预测的是每个 token 自己的隐藏向量。每个 token 接同一个线性分类头
对每个 token 的输出向量接一个 Linear,参数共享输出该 token 的类别。
端到端微调 Linear 层随机初始化,BERT + Linear 一起训练。
