
Self-attention
Self-attention
1. 为什么要有Self-attention
神经网络接收的输入是很多大小不一的向量,并且不同向量向量之间有一定的关系,但是实际训练的时候无法充分发挥这些输入之间的关系而导致模型训练结果效果极差。比如机器翻译问题(序列到序列的问题,机器自己决定多少个标签),词性标注问题(一个向量对应一个标签),语义分析问题(多个向量对应一个标签)等文字处理问题。
针对全连接神经网络对于多个相关的输入无法建立起相关性的这个问题,通过自注意力机制来解决,自注意力机制实际上是想让机器注意到整个输入中不同部分之间的相关性。
2. Q K V的流程
直观理解
Self-Attention = 用 Q 去“问问题”
用 K 判断“谁能回答这个问题”
用 V 把“真正的信息内容”取出来。
输入与输出
输入是一个向量的序列,有个向量到,在下面的图中的矩阵里面,每一列就是一个向量。
输出是
流程
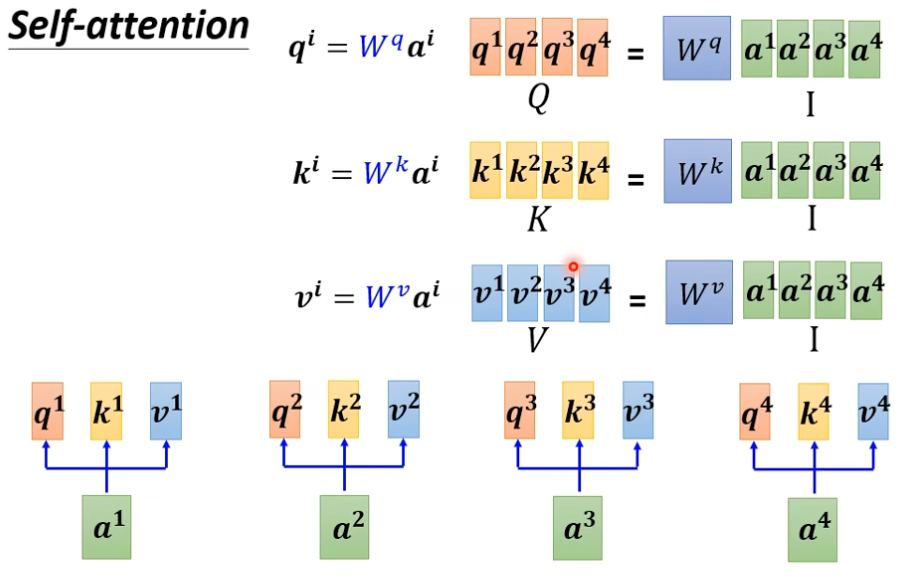
- 由输入生成,通过将每个向量乘上,得到矩阵。其中可以吧所有的向量合并到一起变成一个大矩阵,把所有的合并变成大矩阵,用分别乘,最终得到。
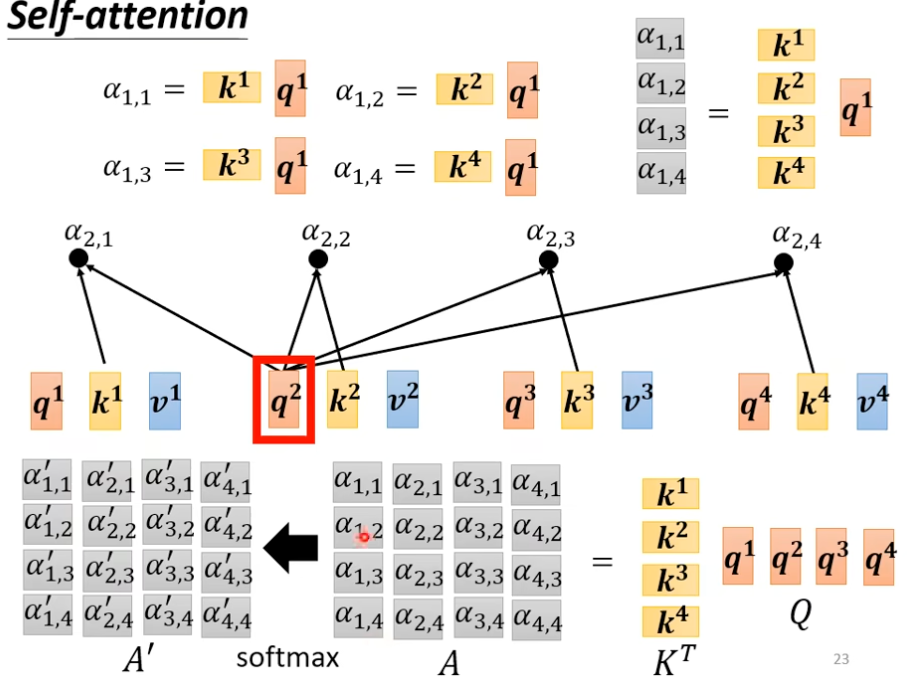
- 用,来计算注意力分数,然后可以根据一个激活函数,把分数矩阵变为。
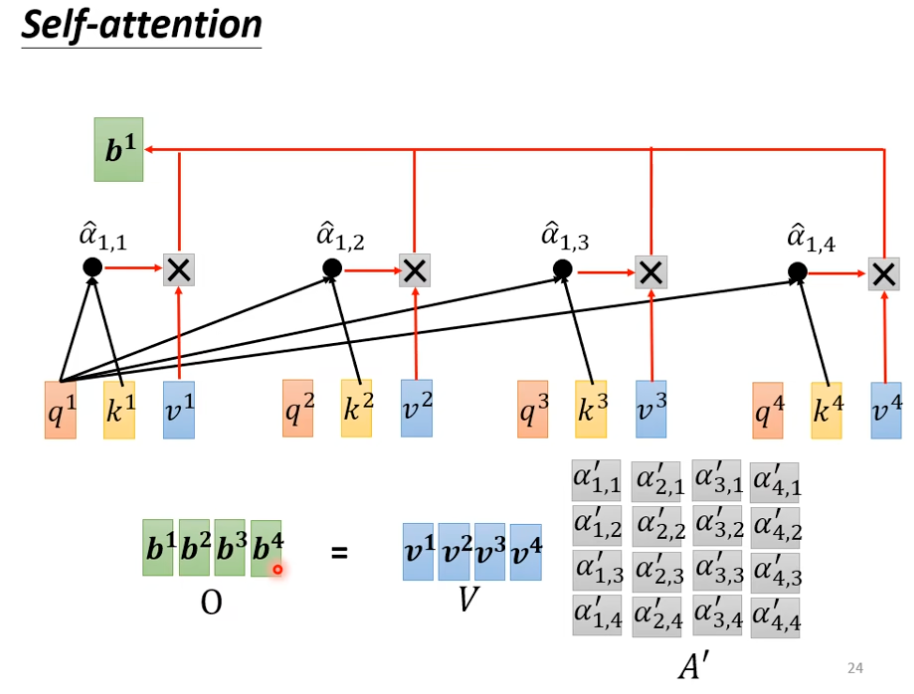
- ,用 Attention 权重加权 Value,最终的矩阵表示输出的新向量的集合。
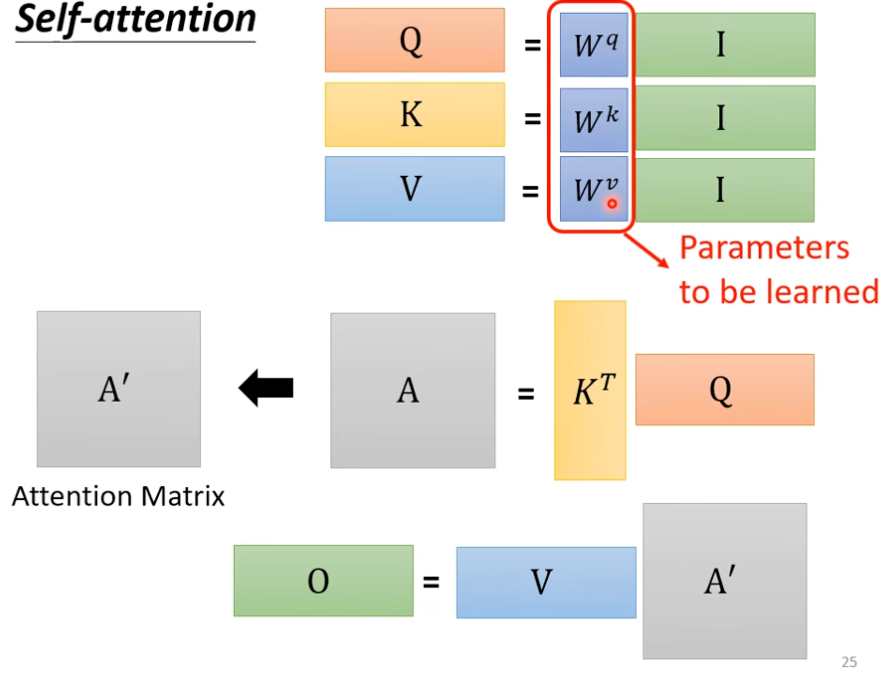
- 整个流程如下,整个过程只有红框的三个矩阵是未知的,需要训练。
3. Multi-head Self-attention
在多个子空间中并行执行 Self-Attention,学习不同的关注模式, 再将各个 head 的结果融合,提升模型表达能力。
- 每个 head 拥有独立的
- 输出序列长度与输入序列长度一致
4. Positional Encoding(位置编码)
Self-Attention 本身不包含顺序信息,
Positional Encoding 用于让模型感知 token 的位置(顺序)。
